
Analysis of Transformer Model Structure
Overview
In the last post, we explored the Attention Mechanism, a revolutionary concept in the NLP field. We covered the motivation behind its creation, how it works, and even delved into Self-Attention, which was proposed to adapt the mechanism for the Transformer model.
To quickly recap, the performance of RNN-based models was significantly hampered by two major issues: information loss as input sequences get longer, and the difficulty of parallelizing training.
The Attention mechanism was introduced to solve these problems. However, the sequential nature of RNNs still acted as a bottleneck, preventing prediction performance from surpassing a certain threshold.
Then, in 2017, a research team from Google published the paper "Attention Is All You Need," introducing the groundbreaking ideas of Self-Attention and the Transformer. This marked the beginning of exponential growth in the field of Natural Language Processing (NLP).
As of writing this on September 26, 2025, the latest models from what you might call the "big three" of LLMs (though they are technically LMMs - Large Multimodal Models, I'll use the more popular term LLM) are OpenAI's GPT-5, Google's Gemini-2.5 Pro, and xAI's Grok-4 Heavy. Would you believe that the Transformer model is essentially the mother of all these LLMs? That's how critically important it is.
The Transformer model might sound intimidating, but its structure is surprisingly straightforward. Therefore, the goal of this post is to walk through the architecture of the Transformer model, making it easy for anyone to understand. We won't get bogged down in every minute detail. Later on, when I have more time, I plan to explore some of the more intriguing aspects, like why the original paper uses sine and cosine functions for positional encoding.
Overall Structure of the Transformer Model
To understand the Transformer, we first need to see how its components fit together to form the complete architecture.
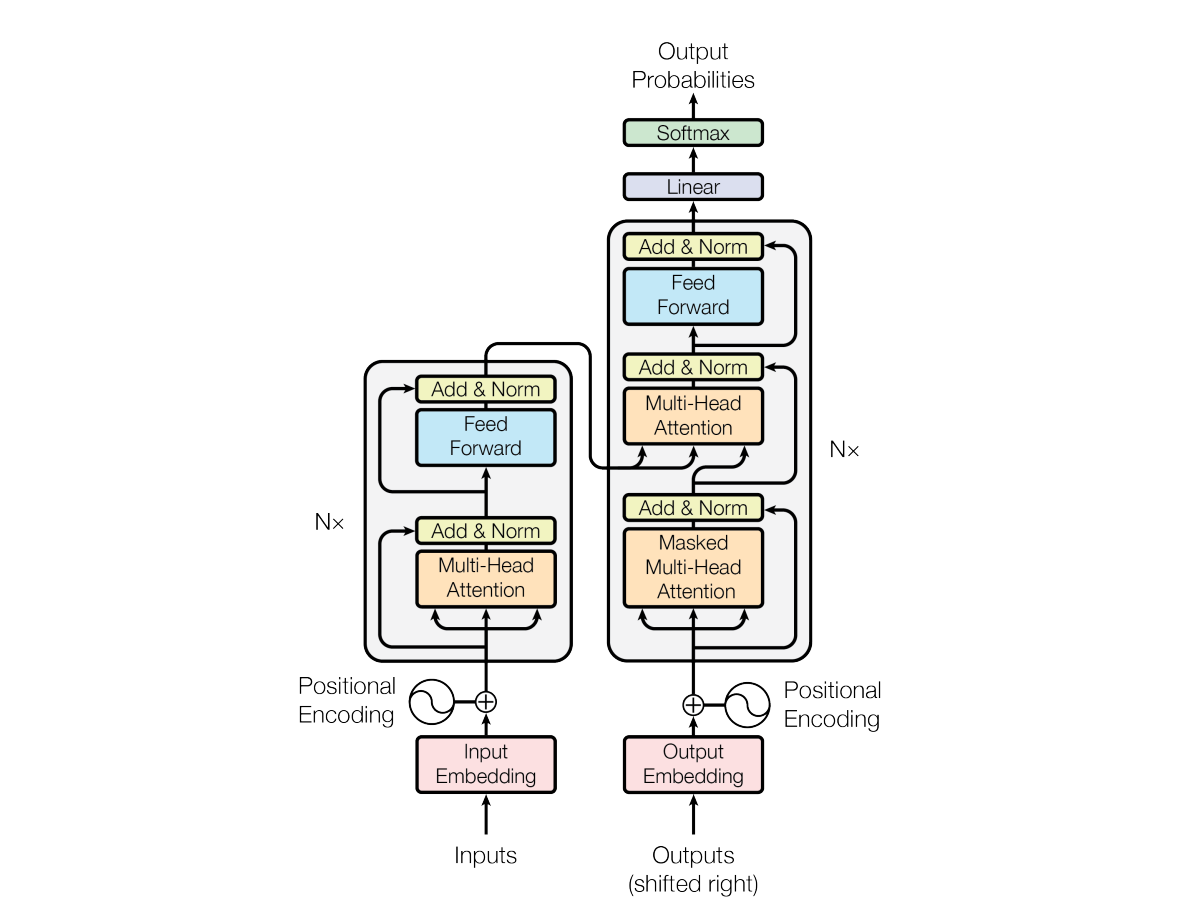
The Transformer fundamentally adopts the Encoder-Decoder mechanism from the Seq2Seq model, which was the dominant paradigm in NLP before the Transformer's arrival. However, the key difference lies in the layers that make up the encoder and decoder. In the Transformer, these layers use the Self-Attention mechanism, and the resulting output vectors carry different semantic meanings compared to those in traditional Seq2Seq models.
To follow this post, it is assumed you have a basic understanding of Attention and Self-Attention. If you need a refresher, please refer to this post.
Now, let's break down the components of the Transformer model one by one to understand its structure.
Input Embedding and Positional Encoding
To make things easier to follow, let's assume our goal is to take the English sentence "I love you" as input and produce the Korean sentence "나는 너를 사랑해" as the final output probabilities.
The first steps our input goes through in the Transformer are Input Embedding and Positional Encoding.
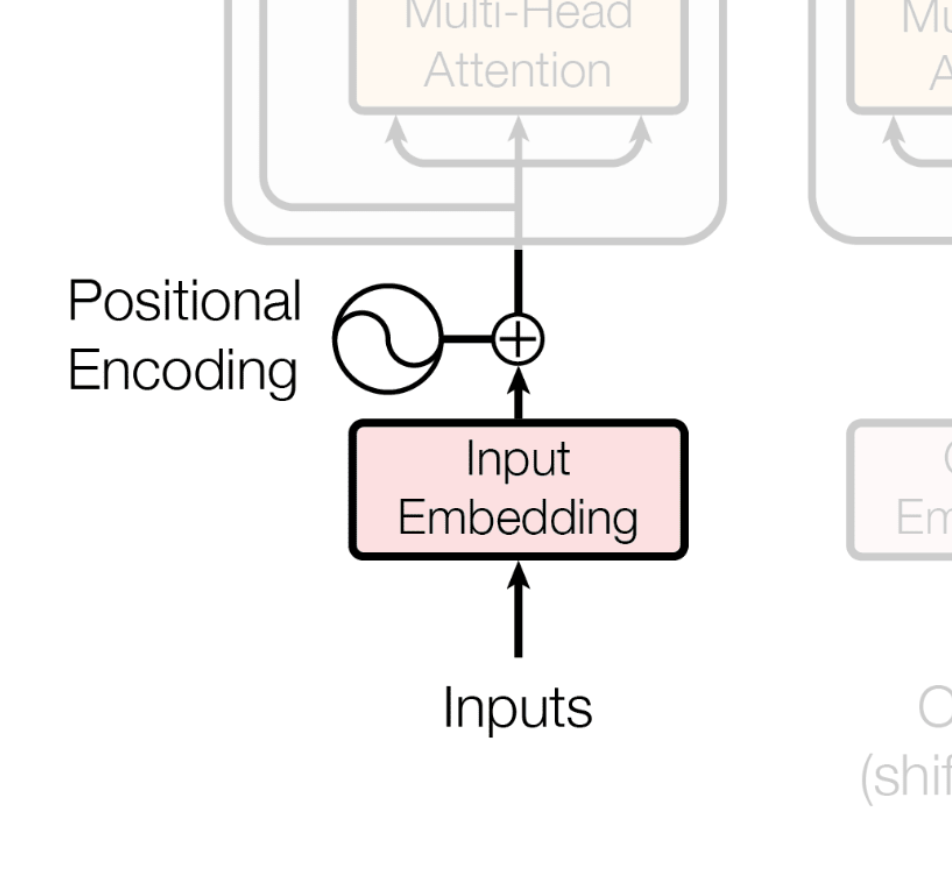
We understand the meaning of the words 'I', 'love', and 'you' because English is a language we use. A computer, however, does not. Therefore, we must convert these words into a format the computer can understand: vectors. This process is called Input Embedding.
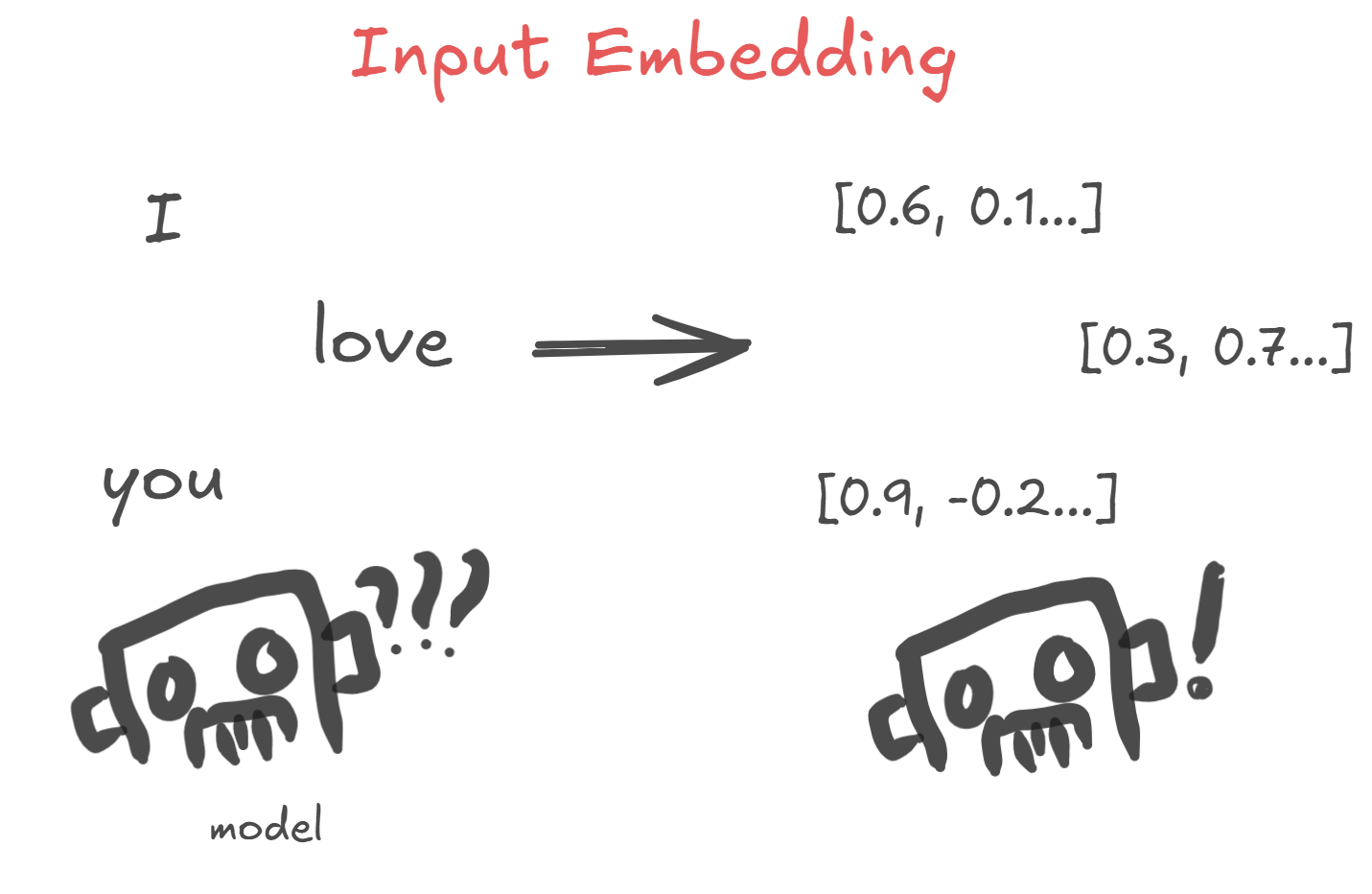
So, can we just feed these converted vectors directly into the model? Not quite. An input embedding is essentially a 'dictionary'. The source language is one we understand ('natural language'), and the target 'words' are vectors that a computer understands. Because it works like a dictionary, the same word will always be converted into the same vector.
But consider the word 'you' in these two sentences:
- I love you.
- You love me.
In the first sentence, 'you' is the object of my affection. In the second, 'you' is the subject who loves me. This distinction is clear to us because we understand the language, but a model that only looks up words in its dictionary will convert both instances of 'you' into the exact same vector. In other words, it completely ignores positional information.
This wasn't a common problem for RNN models because their sequential structure—like dominoes where the previous vector influences the next—allowed the model to figure out if 'you' was the subject or object. However, the Self-Attention mechanism, designed to maximize computational efficiency, doesn't favor this sequential approach.
Therefore, we need to perform a task called Positional Encoding to help the model distinguish between these two 'you's.
Positional Encoding is like giving the model information about where a particular vector exists within the entire sequence. It's similar to how we understand that the word appearing right after the verb 'love' is likely the object of the affection.
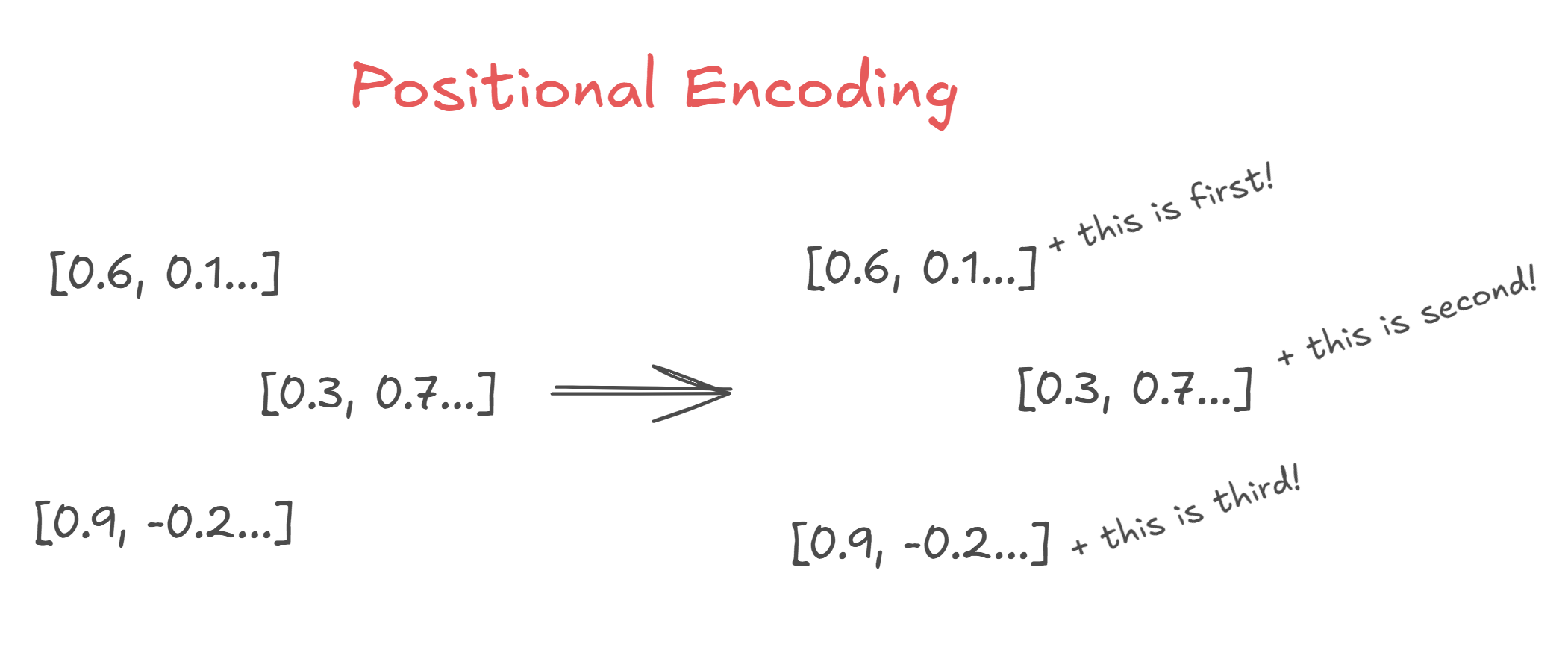
Positional Encoding represents this location information by adding a specific vector value to the word embeddings (the image uses natural language for easier understanding). The original paper stated that using sine and cosine functions can effectively represent this positional information. I'll admit I don't fully grasp the mathematical intricacies yet, but from what I've gathered, the reasoning lies in the properties of periodic functions and the phase-shift relationship between sine and cosine. I plan to study this more in the future.
After completing Input Embedding and Positional Encoding, our original sentence is transformed into a set of vectors that contain both semantic meaning and positional information.
Multi-Head Attention (Encoder)
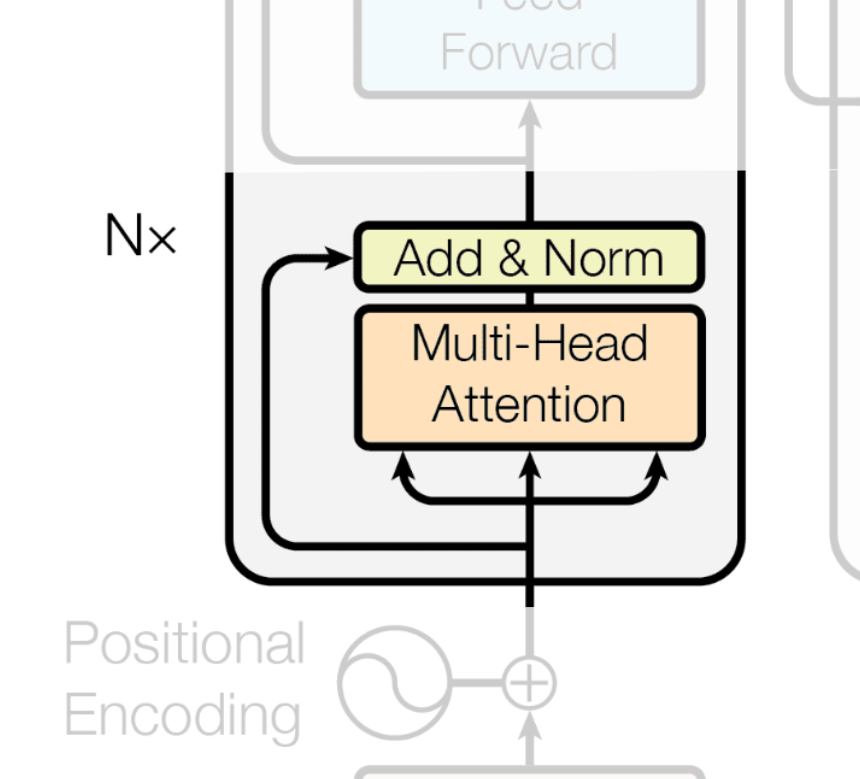
Next, the vectors generated are fed into the Encoder, where the Multi-Head Attention layer performs Self-Attention to understand the relationships between the words in the sentence.
Using Q (Query), K (Key), and V (Value) matrices, the model learns through training to multiply them by weight matrices, gradually getting better at explaining the relationships between words.
Through this training process, in the sentence "I love you," the model learns that 'I' should pay high attention to 'love', 'love' should pay attention to 'I' and 'you', and 'you' should pay attention to 'love'.
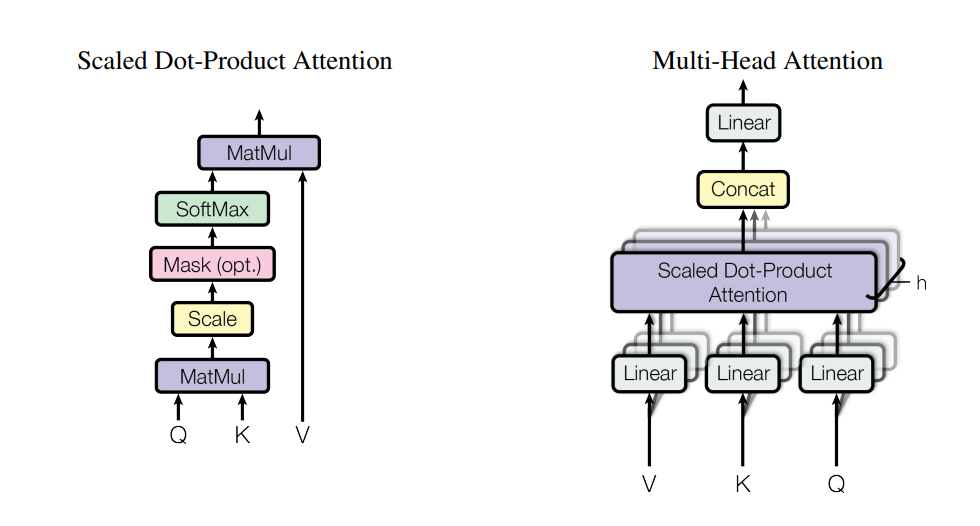
But why is it called "Multi-Head" Attention? As you can see in the image, the left side depicts the standard Self-Attention mechanism we're familiar with. It uses Q, K, and V to perform dot products and generate a single final result vector. This single set of Q, K, and V is called one 'Head'. If we arrange several of these 'Heads', we can obtain multiple result vectors. This is Multi-Head Attention.
Think of it this way: if you get career advice from a single expert, you're likely to follow their specific guidance. However, if you consult several skilled experts, you'll receive slightly different advice based on each one's unique experience. This is precisely the goal of Multi-Head Attention.
After generating multiple result vectors from several Heads, the model concatenates them and transforms them back into a single embedding vector. This allows the model to capture a richer understanding of the relationships within the sentence.
The resulting vectors then pass through an Add & Norm layer. Here, a Residual Connection adds the original input directly to the output, which helps prevent the vanishing gradient problem. Layer Normalization is then applied to stabilize the learning process.
Feed Forward (Encoder)
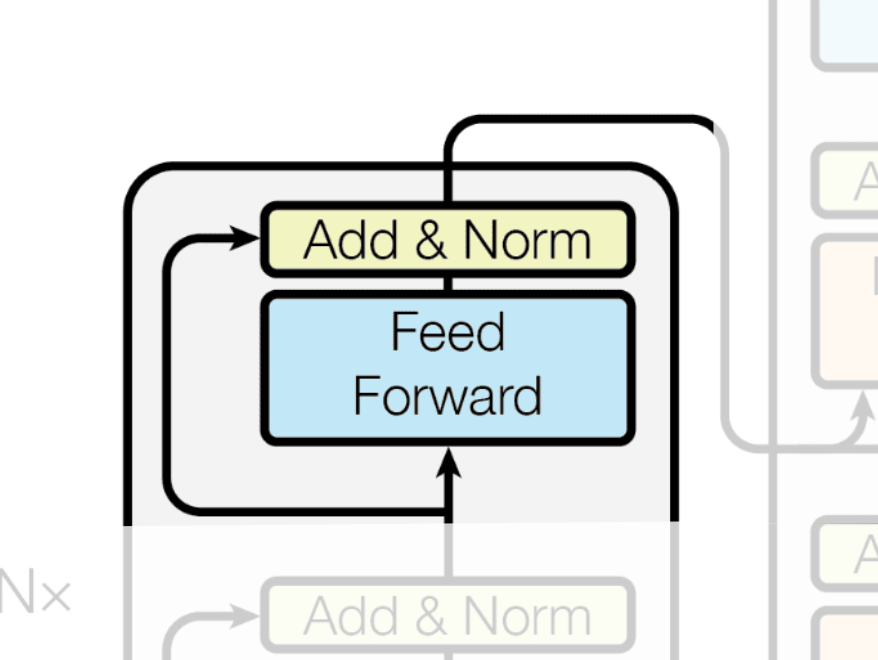
The vectors that have just passed through the Multi-Head Attention layer now contain contextual information about their relationships with other words. However, in this process, they might have lost some of their original, individual meaning. For instance, as the vector for 'I' absorbed information from 'love' and 'you', its own identity as 'I' might have become slightly diluted.
To counteract this, we need a way for the tokens to be processed non-linearly without influencing each other, allowing them to re-emphasize their original information without losing the newly acquired context. The Feed-Forward Network achieves this by expanding the vector's dimension, applying a non-linear transformation, and then projecting it back to its original size.
Like before, the vectors from the Feed-Forward layer also pass through an Add & Norm layer to maintain training stability.
This completes the overall structure of the Encoder, which ultimately outputs a set of refined vectors containing positional, contextual, and semantic information.
Output Embedding & Positional Encoding
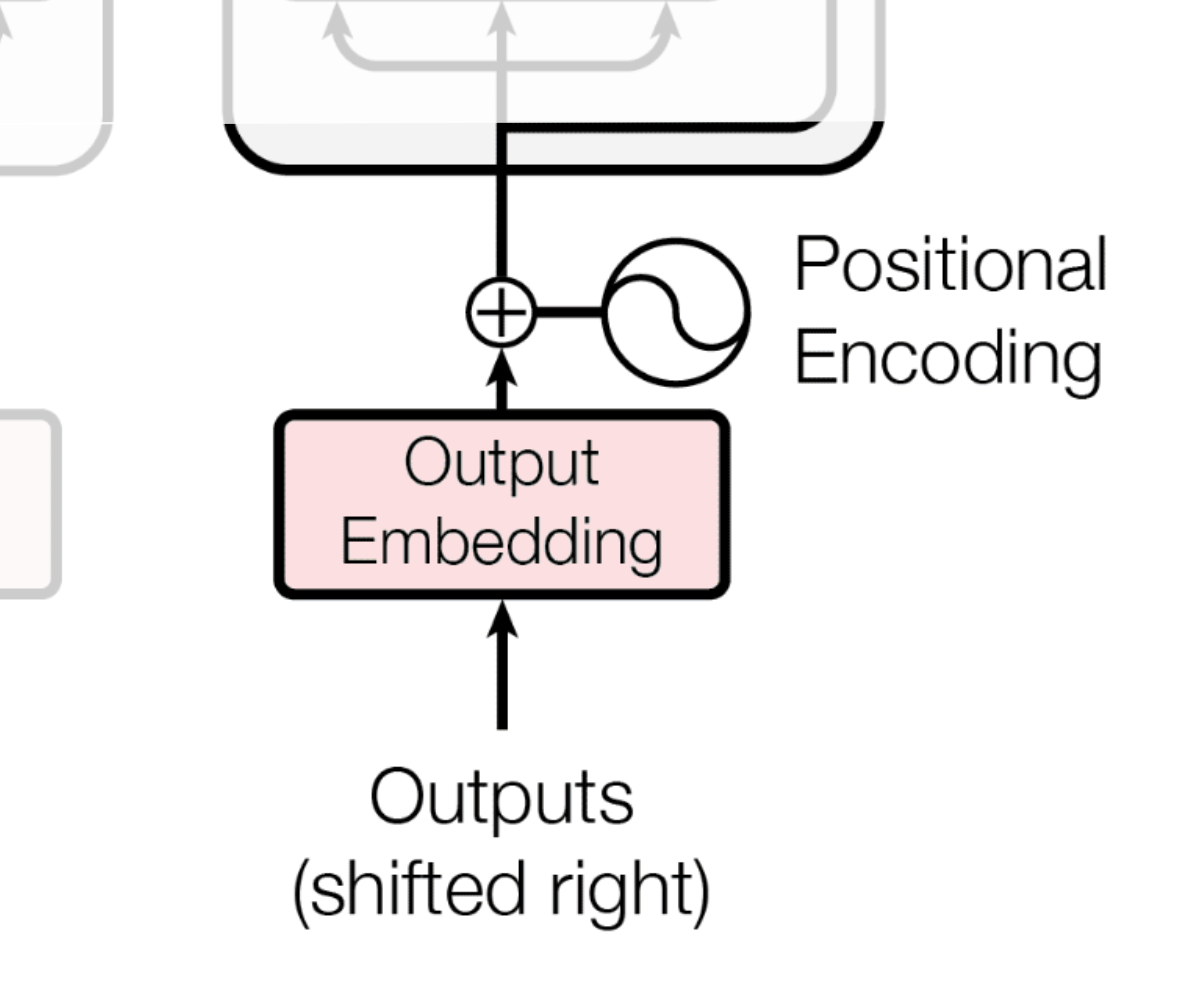
The Decoder's input has a recursive structure: the word with the highest output probability from the previous step becomes the input for the next step. In other words, it predicts the next word in the sentence one by one, using the sentence it has generated so far.
However, at the very beginning, no words have been predicted yet. So, we use a special start-of-sentence token, <SOS>, as the initial input to the decoder.
Just like in the encoder, this <SOS> token is converted into a vector, and positional information (for the first position) is added to it.
Masked Multi-Head Attention (Decoder)
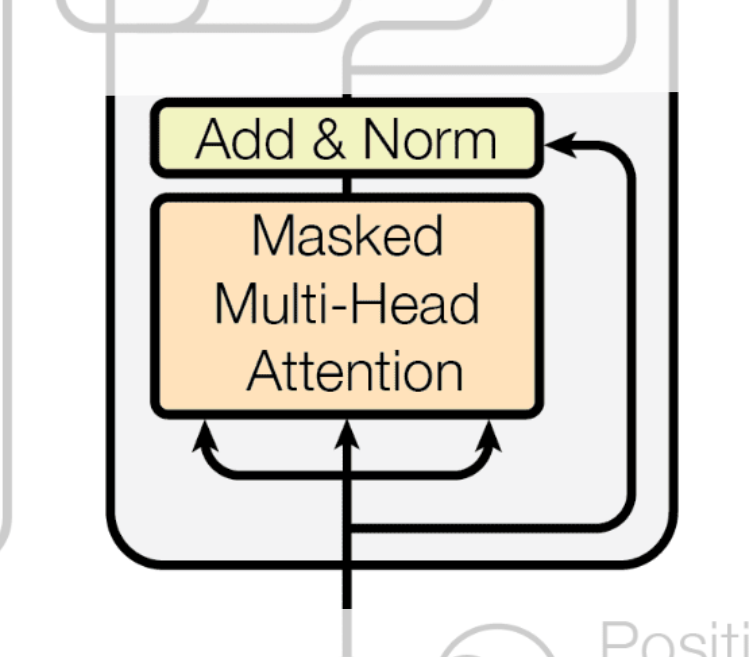
The Masked Multi-Head Attention layer serves the same purpose as the Multi-Head Attention layer in the Encoder: to perform multi-headed self-attention on the decoder's inputs to understand their interrelationships.
But what does the word "Masked" signify? It refers to a technique called masking, which is essential during the training of the Transformer model.
The model we ultimately want is one that predicts the next word based only on the words it has generated so far. During training, however, the decoder is fed the entire correct target sentence (the "answer key"). If we performed regular self-attention, the model would "cheat" by looking ahead at the words it's supposed to be predicting.
To prevent this, we apply a mask. The mask effectively hides or "masks out" all future tokens, ensuring the model only pays attention to the tokens up to its current prediction point. In Self-Attention, this is done by adding negative infinity to the scores of the masked positions right before the Softmax step, which turns their probabilities to zero.
After passing through Masked Multi-Head Attention, the decoder's input vectors now hold contextual information about the relationships between tokens up to the current position.
Again, the output vectors go through an Add & Norm layer for stability.
Multi-Head Attention (Decoder)
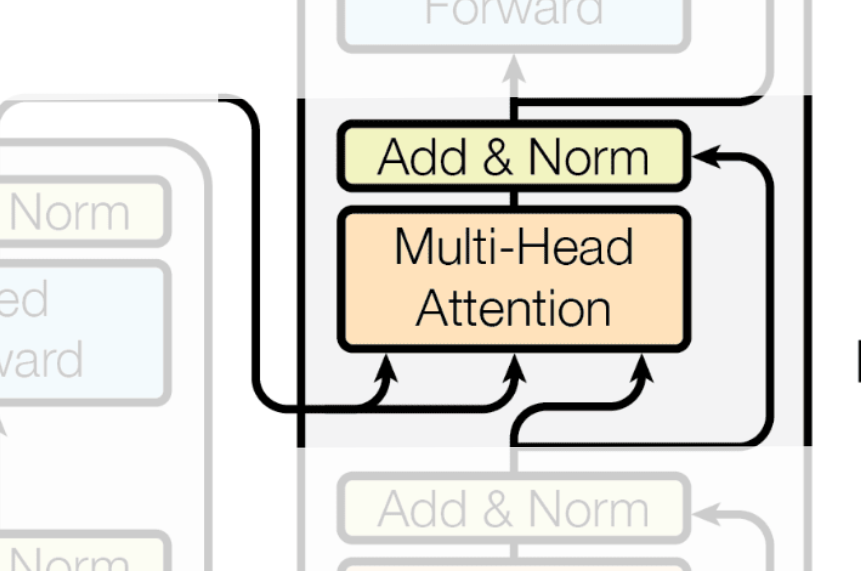
Now we've arrived at my favorite layer in the Transformer model. The first time I saw this, I was amazed at how they came up with such an ingenious idea.
By now, you've probably noticed that the arrows in the diagram represent inputs. If you look at the diagram for this layer, you'll see two arrows coming from the encoder's output and one coming from the output of the previous Masked Multi-Head Attention layer.
This is the key. We are going to perform attention, but this time, the Q (Query) matrix comes from the decoder's output (from the previous step), while the K (Key) and V (Value) matrices come from the encoder's final output—the vectors that hold the context of the original source sentence.
In our example, the decoder's current output (<SOS>) will use this mechanism to determine that it has a strong relationship with the encoder's output for 'I'.
This structure is also known as Cross-Attention or Encoder-Decoder Attention.
As always, the resulting vectors are passed through an Add & Norm layer.
Feed Forward (Decoder)
This layer serves the same function as the one in the encoder. It further processes the information obtained from the Cross-Attention step, allowing for deeper, non-linear transformations.
Linear & Softmax
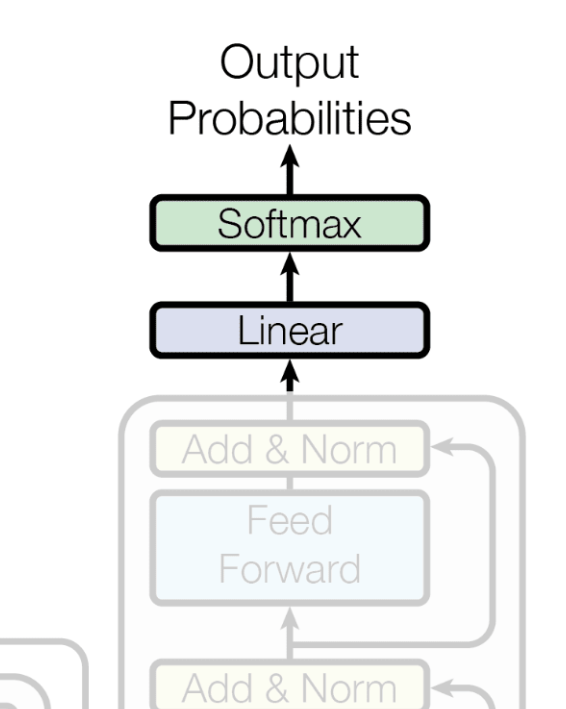
Finally, we predict the next word in the sequence.
- Linear: The final vector from the decoder block is passed through a linear layer, which expands its dimension to the size of our entire Korean vocabulary. Each dimension represents a "score" for a specific word.
- Softmax: The softmax function converts these scores into probability values between 0 and 1. The sum of all word probabilities equals 1.
The word with the highest probability—for example, '나는' ('I')—is selected as the first word of the translated output.
This entire process repeats, generating the next word based on the sequence produced so far, until the final sentence '나는 너를 사랑해' is returned.
Conclusion
The core idea of the Transformer's architecture is a recursive process: it first understands the relationships within the input sentence, and then, to generate the output sentence, it repeatedly selects the next word that has the highest relevance to both the input sentence and the output generated so far.
Breaking it down like this, the Transformer model seems to have a relatively simple Encoder-Decoder structure after all. I found the Cross-Attention part particularly fascinating and believe it's a key reason for the Transformer's high accuracy.
Additionally, although I didn't mention it earlier, most of the computations in the Transformer are based on Self-Attention, which can be highly parallelized, allowing for maximum utilization of computing resources.
I wrote this post very late at night, so I'm aware there might be mistakes and parts that were written in a rush;;; Thank you for reading all the way to the end. In the next post, I plan to analyze the GPT-2 architecture to explore how the Transformer model has evolved.
References
- Attention Is All You Need - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin | Original paper
- Attention/Transformer 시각화로 설명 | ImcommIT youtube channel
- 트랜스포머, ChatGPT가 트랜스포머로 만들어졌죠. - DL5 | 3Blue1Brown 한국어 youtube channel
- 그 이름도 유명한 어텐션, 이 영상만 보면 이해 완료! - DL6 | 3Blue1Brown 한국어 youtube channel
- [딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) | 동빈나 youtube channel
- [Deep Learning 101] 트랜스포머, 스텝 바이 스텝 | 신박Ai youtube channel
- 트랜스포머 모델이란 무엇인가요? | IBM
- 트랜스포머 모델이란 무엇인가? (1) | NVIDIA Blog
- 트랜스포머 모델이란 무엇인가? (2) | NVIDIA Blog
- Materials learned from a surprisingly large number of LMMs and the internet.