
Attention And Self-Attention. Why They Important?
Overview
I've recently been diving into the field of Natural Language Processing (NLP). It's incredibly fun, exciting, and feels entirely new to me. Just a year ago, I had absolutely no idea how LLMs (Large Language Models) like ChatGPT, Gemini, and Grok worked internally. My knowledge was limited to the basic idea that an LLM receives user input, probabilistically selects words internally, and then delivers those selected words as the final output.
However, since becoming deeply interested in NLP, I've been studying everything from the basics of AI like machine learning, Neural Networks, MLP, CNN, and now RNNs. Recently, I've been focusing on RNNs, and to better understand my field of interest, NLP, I'm also studying Attention, Self-Attention, and the Transformer model.
In today's post, I want to summarize what I've understood about Attention and Self-Attention and discuss the history of how they became so important in the NLP field.
The Background of Attention: The Limits of Seq2Seq
First, we need to understand: "How did Attention come to be?"
The emergence of the Attention Mechanism can be traced back to the Seq2Seq (Sequence-to-Sequence) model, an RNN (Recurrent Neural Network)-based model proposed to solve machine translation problems. At the time, the Seq2Seq model, which used an Encoder-Decoder architecture, had the following limitations:
-
Fixed-length Context Vector: The encoder had to compress all the information from an input sentence into a single, fixed-size vector. This created a 'bottleneck,' causing information loss as sentences got longer, which in turn degraded the quality of the translation.
-
Long-term Dependency Problem: A chronic issue with RNNs, where important information from the beginning of a sentence fades as it progresses, failing to be properly transmitted to the end.
In simple terms, the very nature of RNNs meant that the importance of earlier information was bound to diminish as the context grew, leading to direct performance issues in the model.

A loose analogy for this is how rumors get distorted in our daily lives. You've probably experienced a rumor spreading from person to person, becoming completely different from the original story by the time it reaches you. You can think of the Seq2Seq model having a similar limitation.
Consequently, many researchers worked to solve these problems. In 2015, researchers from the University of Montreal, including Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio, published a monumental paper titled "Neural Machine Translation by Jointly Learning to Align and Translate." It was in this paper that the concept of 'Attention' was first proposed.
The Advent of Attention, The Evolution of the Context Vector
The initial concept of Attention was as follows: "At each time step, when the Decoder generates a word, it refers to a Context Vector created by 'attending' more closely to specific parts of the input (Encoder) sequence." This was the core idea of Attention first proposed in the paper.
In other words, in an RNN model without Attention, the Context Vector is generated only once at the beginning. When the output layer generates the output sequence, it has to rely solely on this single Context Vector, which is susceptible to information loss. However, with Attention, when generating a specific token, the model can refer to a Context Vector that better represents the information related to that token, thus improving performance.
Here is a diagram illustrating this:
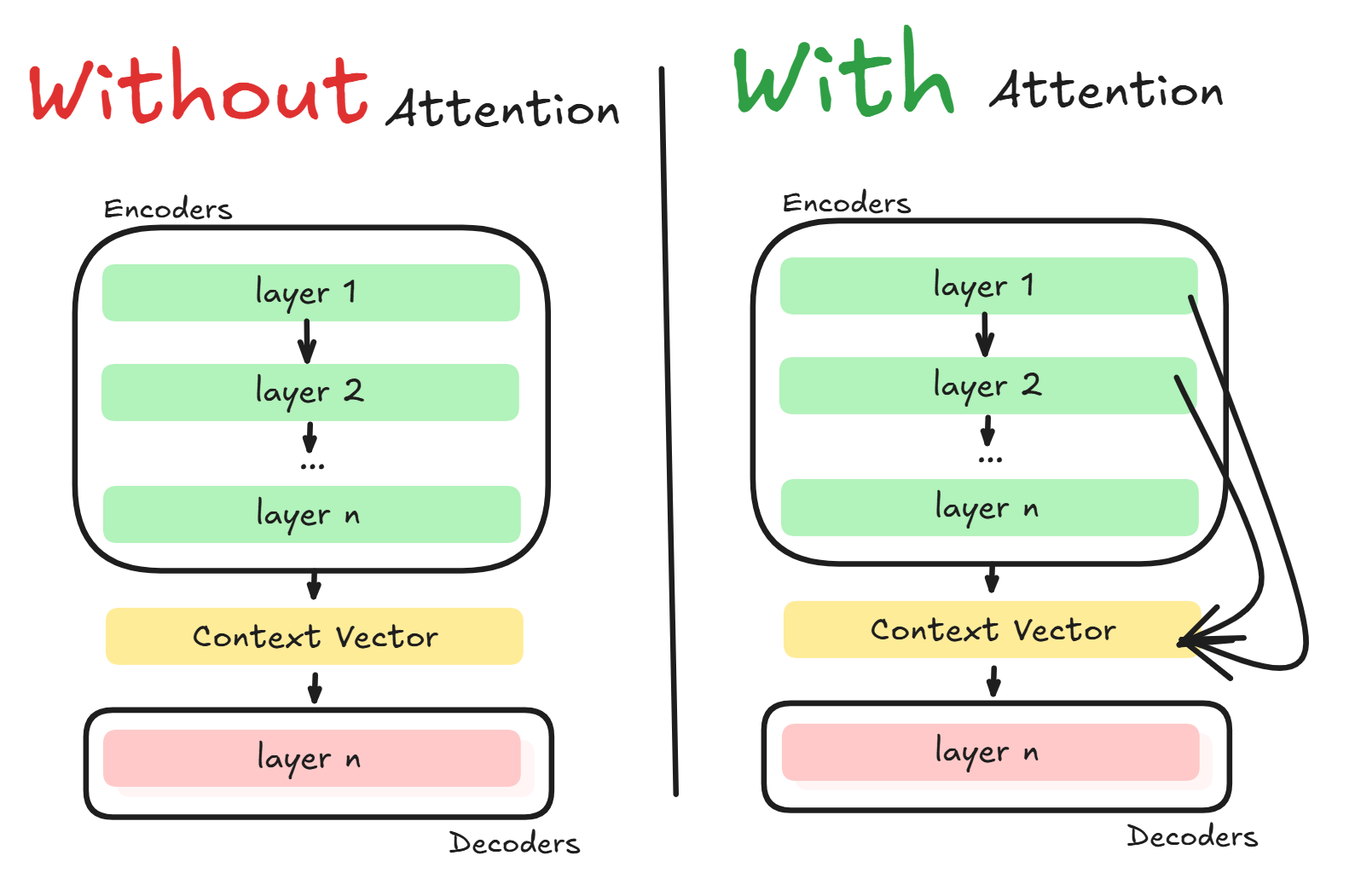
Although this is a very simplified diagram and not perfectly accurate, I wanted to show the high-level difference in how information is packed into the Context Vector with and without Attention.
Now, let's take a closer look at how Attention works.
How Attention Works
To understand the main operational process of Attention, we first need to know about its core components: Q (Query), K (Key), and V (Value).
The Core Components of Attention: Q, K, V
-
Q (Query): The Query is the decoder's hidden state at the current time step, representing the token it's using to generate the next part of the sequence. The Query essentially asks the encoder which tokens have the information needed to generate the next token. For example, let's say we are translating the Korean sentence "나는 너를 사랑해" ("I love you") into English. If we have translated up to "I" and need to generate the next word, "love," we need to see what the word "I" is related to. In this case, the Q (Query) becomes "I" (technically, 'I' multiplied by a query weight matrix Wq), and it conveys the question, "What word is 'I' related to?"
-
K (Key): The Keys are the tokens (hidden states) generated by the encoder, and they are the targets that the Query seeks. Typically, if a Query and a Key are highly related, the scalar value resulting from their dot product (also known as the Attention Score) will be high. In our previous example, to generate the word after "I," we compared the Query "I" with the encoder's words. Here, the encoder's words correspond to the Keys. The Key that would show high attention with "I" would likely be "사랑" (the Korean word for "love").
-
V (Value): The Value represents the actual information of the Q-K relationship. In standard Attention, the Key and Value are often the same. The Value is used to embed new information for the Query, weighted by the attention score, into the Context Vector. In our example, we confirmed that "I" (Q) and "사랑" (K) have a high attention score. Therefore, this information will be included in the Context Vector, and finally, the model will predict the next word as "love," the English translation of "사랑," by referencing this context.
Having briefly looked at Q, K, and V, we've touched upon the general process of Attention. Let's review the steps one more time.
The Attention Process
- The Encoder converts input tokens into Keys and Values.: The Encoder reads the entire input sequence and generates a set of information vectors (Hidden States) for each input element. This set of vectors serves as the Keys (for reference) and Values (the actual information) that the decoder will later consult.
- The Decoder dynamically generates output elements: The following steps are repeated for each output element (token) generated.
-
Generate Q (Query): Based on the output generated so far and its own internal state, the decoder creates a Q (Query) about what information is needed next.
-
Calculate Scores: The generated Query is compared with all of the encoder's Keys to calculate an 'attention score' for each, indicating the relevance to the current Query.
-
Convert to Weights: The calculated scores are passed through a softmax function to be converted into Attention Weights that sum to 1. These weights represent the 'degree of focus' or 'importance' of each input element.
-
Create Context Vector: These attention weights are multiplied by the encoder's Values and then summed up to create a single, optimized Context Vector for the current time step. This vector is the result of 'emphasizing important information and ignoring unnecessary information.'
-
Final Prediction: The decoder considers its current state along with this tailored Context Vector to finally predict the next element in the output sequence.
-
We now have a basic understanding of how Attention works. However, even Attention couldn't solve all of RNNs' problems, due to their fundamental limitations. Let's explore what those limitations were and how Attention evolved to overcome them.
Attention Hits RNN's Limits: The Emergence of Self-Attention
As we've discussed, Attention allows the decoder to look at all the information in the encoder and pick the most relevant tokens when generating a new token. But we must not forget something crucial: the tokens (K, V) in the encoder are themselves products of an RNN and thus still carry the Long-term Dependency Problem.
The tokens include contextual information by referencing the previous hidden state, but due to the limitations of RNNs, earlier information is bound to be lost as the sequence gets longer.
Furthermore, RNNs are like dominoes; they cannot compute the context of the next word until they have understood the context of the previous one. The model's calculations must proceed sequentially, like this: ------>. This prevents leveraging the full power of GPUs (Graphics Processing Units), which are central to training modern AI models.
To summarize, Attention had two main limitations:
- Lack of parallel processing due to sequential computation
- The still-present Long-term Dependency Problem
Therefore, a new Attention Mechanism emerged to overcome these limitations: Self-Attention.
Let's explore what Self-Attention is and how it solved these problems.
Self-Attention: Attention Is All You Need.
The concept of Self-Attention was first introduced in 2017 in a paper from the Google research team titled "Attention Is All You Need."
This paper was actually published to introduce a new model, the 'Transformer,' which aimed to completely eliminate the sequential structure of RNNs. The mechanism that the Transformer model uses to understand contextual and attentional relationships is Self-Attention.
However, since Self-Attention is used in almost all computations within the Transformer model, it's fair to say that without the concept of Self-Attention, the Transformer model would not exist.
In any case, this is how Self-Attention was introduced to the world. Self-Attention allows every word in a sentence to be directly connected to every other word, enabling the model to figure out which words are important to each other in a single calculation. This allows it to learn dependencies regardless of the distance between words and to process all calculations in parallel. This combination of speed and performance gave birth to the Transformer architecture.
Now, let's dive deeper into the operational structure of Self-Attention.
How Self-Attention Works
Self-Attention is a process where words within a sentence ask and answer questions among themselves to enrich their own meaning. It works much like people at a networking party who clarify their roles by talking to each other.
All operations in Self-Attention occur simultaneously and in parallel, as it was designed to maximize GPU efficiency.
Like Attention, Self-Attention also has the core components of Q, K, and V. However, they operate slightly differently. Let's take a look.
Q, K, V in Self-Attention
First, each token in the sentence is assigned three different roles. By multiplying the base vector (embedding) of each word by three different weight matrices (Wq, Wk, Wv), three new vectors are created: Q (Query), K (Key), and V (Value). These matrices map the input vectors into different semantic spaces, allowing them to perform their distinct roles.
- Q (Query): The generated Q (Query) vectors are oriented towards finding their associated K (Key) vectors.
- K (Key): The generated K (Key) vectors are oriented to better express their own characteristics (so that Q vectors can find their related K vectors).
- V (Value): Each generated V (Value) vector contains the actual information of a specific K vector. This allows Q to find the actual value through V once it has found K.
As you can see, Q, K, and V play roles very similar to those in standard Attention. Now let's see how these core components work in the actual process.
The Self-Attention Process
Before we dive into the process, there's a crucial rule that the vectors used in Self-Attention must follow: they must contain 'positional information.'
In RNNs, positional information is naturally included as hidden states are passed along sequentially with context. In contrast, while Self-Attention learns contextual information during its operation, it cannot learn positional information. Therefore, positional information must be embedded into the vectors before the Attention operation is performed. This is called Positional Encoding. In simple terms, by including positional information in the vectors, even if identical vectors appear in the same sentence, the vectors they are related to will differ based on position.
Now, here is the process for Self-Attention:
-
Calculate Attention Scores: To compute the contextual representation of a specific element, its Q (Query) vector is dot-producted with the K (Key) vectors of all elements in the set to calculate scores. This process is efficiently done all at once by grouping all Query and Key vectors into matrices Q and K. The matrix of attention scores generated here is sometimes called an Attention Map.

Source: https://slds-lmu.github.io/seminar_nlp_ss20/attention-and-self-attention-for-nlp.html An example of an Attention Map.
-
Scaling and Normalization: The calculated attention scores can vary greatly in magnitude depending on the dimension of the K vectors, which can destabilize the training process. To prevent this, the scores are scaled by dividing them by the square root of the K vector's dimension. Afterward, the Softmax function is applied to the scaled scores to normalize them so that their sum equals 1.
-
Generate Output Vector via Weighted Sum: Finally, each element's V vector is multiplied by its corresponding attention weight, and all are summed up to produce the final output vector for element i. This output vector contains information from all elements in the set but is weighted more heavily with information from elements that are highly relevant to itself, resulting in a contextually rich new representation.
The generalized formula for the vector produced through Self-Attention is as follows:
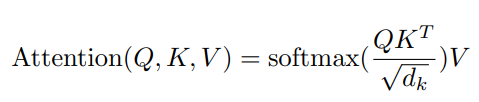
The final vector generated after this entire process now holds both contextual and positional information without the risk of context loss.
Conclusion
In this post, we explored the Attention Mechanism, which emerged to solve the problems of the Seq2Seq RNN model, and the limitations it faced. We then looked at Self-Attention, the mechanism that was developed to overcome those limitations.
In fact, the Self-Attention mechanism is adopted by most modern LLMs and LMMs (Large Multimodal Models) and can be credited with making a significant contribution to the revolutionary growth of the NLP field.
After examining how Attention and Self-Attention actually work, I think I have a slightly better understanding of why sentence generation in LLMs is often described as a series of probabilities. To truly grasp this, I need to look into the Transformer model itself, which is what I want to analyze and understand in my next post.
References
- Attention Is All You Need - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin | Original paper
- Attention/Transformer 시각화로 설명 | ImcommIT youtube channel
- 트랜스포머, ChatGPT가 트랜스포머로 만들어졌죠. - DL5 | 3Blue1Brown 한국어 youtube channel
- 그 이름도 유명한 어텐션, 이 영상만 보면 이해 완료! - DL6 | 3Blue1Brown 한국어 youtube channel
- [딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) | 동빈나 youtube channel
- Materials learned from a surprisingly large number of LMMs and the internet.