
An Analysis of the GPT-2 Architecture and a Foray into Fine-Tuning
Overview
In the last post, we looked at 'GPT-1' and 'BERT', Transformer-based models that marked a milestone in the development of natural language processing. 'GPT-1' was a model that maximized its 'generation' capabilities by removing the Transformer's encoder and using only the decoder, excelling at tasks based on sentence generation. In contrast, 'BERT' removed the decoder and used only the encoder, maximizing the encoder's 'contextual understanding' ability to perform well on tasks like sentiment analysis, summarization, and masked word prediction.
Thus, both 'GPT' and 'BERT' originated from the Transformer, ultimately proposed to maximize specific technologies.
However, starting with 'GPT-2', the landscape began to shift slightly. As 'GPT-2' added about 10 times more parameters than 'GPT-1', the possibility emerged that a pre-trained 'GPT-2' could, albeit immaturely, perform various tasks. This was fully proven when 'GPT-3' added about 1,500 times more parameters than 'GPT-1', showing that a pre-trained model alone was sufficient to perform multiple tasks.
So, let's delve into 'GPT-2', which triggered the mechanism change from 'GPT-1' to 'GPT-3', find out what makes it different, and see what it looks like when fine-tuned.
Note: This post was written after the completion of a GPT-2 structural analysis and fine-tuning project. It consists of a retrospective on the process and a detailed explanation of some of the theories. For the exact code, please refer to the iamb0ttle/GPT-2-Fine-Tuning GitHub repository, which contains detailed comments and code.
GPT-2: The Signal Flare of 'Large' Language Models
GPT-2 is a model released in 2019 by OpenAI, the same non-profit organization (at the time of the paper's publication) that researched GPT-1, about a year after its predecessor. It was first introduced in the paper “Language Models are Unsupervised Multitask Learners” (2019, Radford et al.), published about four months after BERT (October 2018).
While BERT stunned the world with its phenomenal performance on contextual processing benchmarks, it wasn't long before another model, through its massive parameter count, introduced a new innovation to the public.
An interesting fact is that when OpenAI released GPT-2, they did not initially release the largest 1.5 billion (1.5B) parameter model. At first, they released the smallest 117 million (117M) parameter model and only released the larger one after other researchers had replicated similar models. This sparked a debate, with opinions still divided between it being a 'necessary guardrail for safety' versus 'over-hyped, dangerous marketing'.
In any case, the important point is that by using significantly more parameters than GPT-1, GPT-2 performed much better on various tasks, and its general ability to predict the next word improved noticeably.
Now, let's examine the exact differences between GPT-1 and GPT-2.
GPT-1 vs. GPT-2
In truth, since both GPT-1 and GPT-2 are based on the Transformer model's decoder architecture, there are no striking changes or differences in the model structure itself. However, a few key differences set the GPT-1 and GPT-2 models apart.
First, let's compare the differences between the GPT-1 and GPT-2 models in a table.
| GPT-1 | GPT-2 | |
|---|---|---|
| Objective | Fine-tuning based on a pre-trained model | Zero-shot learning performance |
| Model Size | 117 million parameters | 1.5 billion parameters |
| Training Data | BookCorpus (7,000 unpublished books, 1GB) | WebText (Reddit posts, 40GB) |
| Context Size | 512 tokens | 1024 tokens |
| Vocabulary Size | Approx. 40,000 | Approx. 50,257 |
Model Objective: Fine-Tuning vs. Zero-shot
It's no exaggeration to say that the model's objective was a major factor in determining the differences between GPT-1 and GPT-2.
First, GPT-1's objective was clear: "Create a well-trained pre-trained model for various domains, then fine-tune it for multiple applications." Indeed, GPT-1 achieved this goal well. Instead of supervised training of a specific model from A to Z, fine-tuning the unsupervised pre-trained model with a small amount of domain-specific information sometimes yielded better performance than a fully supervised model. However, the vanilla state of GPT-1 without fine-tuning was awkwardly suited for any specific field.
But GPT-2 completely changed this approach. GPT-2's objective was to enable the pre-trained model itself to achieve sufficient zero-shot performance. Zero-shot refers to a model's ability to handle data or tasks it has never seen during training. In other words, the goal was for GPT-2, even if trained solely as a Casual LM, to solve problems like sentiment analysis, translation, and more.
This method was actually successful. When a prompt like "Translate this sentence to English: 안녕 나는 지피티야" is given to a model trained as a casual LM, it outputs "Hello, I'm GPT." However, this depended heavily on the precision of the prompt, which further fueled the trend of prompt engineering. This is a widely used method when we expect a single language model to perform many different tasks.
Model Size: Size Directly Translates to Performance
GPT-2 shocked many with its drastically increased model size. It was released with 1.5 billion parameters, about 10 times more than GPT-1's 117 million, heralding the beginning of the Large Language Model era. This was later capped off by GPT-3's grand finale of 175 billion parameters.
Indeed, substantially increasing the number of parameters had a major impact on model performance. More parameters meant the model could learn a larger volume of information. This allowed GPT-2 to be trained on WebText, a 40GB dataset of high-quality web data from links highly recommended by Reddit users.
Besides the parameter count, GPT-2's size increased in other aspects as well. The context size doubled to 1024 tokens, enhancing the model's ability to understand context. The vocabulary size also grew by about 10,000 words, from roughly 40,000 to 50,257.
Architectural Change: Post-LN → Pre-LN

As mentioned earlier, the model architecture itself is almost identical for GPT-1 and GPT-2.
However, one difference is that GPT-2 used a Pre-LN approach, moving away from the Post-LN method chosen by GPT-1.
Pre-LN means placing the Layer Normalization layer before the main operation to normalize the inputs before they are processed. As seen in the image above, the GPT-1 structure on the left uses a Post-LN method, performing normalization after the Masked Multi-Head Self-Attention. In contrast, the GPT-2 structure on the right uses a Pre-LN method, normalizing the vectors first and then performing self-attention on these normalized vectors.
GPT-2 adopted this Pre-LN method because as the model size and the amount of information to be learned increased, instability in the values entering the attention mechanism could have a deep and pervasive impact throughout the training process. Therefore, to stabilize training from the start and control variables, this Pre-LN method was introduced.
Thus, the GPT-2 model, through these incremental changes from GPT-1, expanded its mechanisms to actively pursue the Zero-shot Learning methodology. In fact, the Hugging Face transformers library provides GPT2Model variants with additional heads for fine-tuning on specific tasks like sentence classification and question answering. Its fine-tuning performance was also greatly improved compared to GPT-1, and the GPT-2 model ultimately became a monumental model that fired the starting pistol for large-scale language models.
What are PEFT and LoRA? Let's Explore Fine-Tuning Techniques
Now that we've looked at the GPT-2 architecture, let's move on to fine-tuning it.
Before that, let's review the goals I planned for this project:
- Fine-tune GPT-2 on a news dataset to generate text in a news style.
- Fine-tune GPT-2 on a dataset of Joker's (from Batman) lines to generate sentences that mimic his speech patterns.
To proceed with this project, I decided to apply a PEFT technique, specifically the LoRA method, for fine-tuning.
Full Fine-Tuning vs. PEFT
First, fine-tuning methods can be broadly divided into two categories: Full Fine-Tuning and PEFT.
- Full Fine-Tuning: This is a method where all the weights of a pre-trained model are updated on new data. It's the most traditional approach, often used when high accuracy on a specific task is desired. However, it can have the disadvantage of requiring a large number of parameters to be trained.
- PEFT (Parameter-Efficient Fine-Tuning): Unlike Full Fine-Tuning, PEFT does not update all of the model's parameters. Instead, some parameters are frozen (their weights are not updated during training), and only a subset of parameters are updated, or new parameters are added and updated.
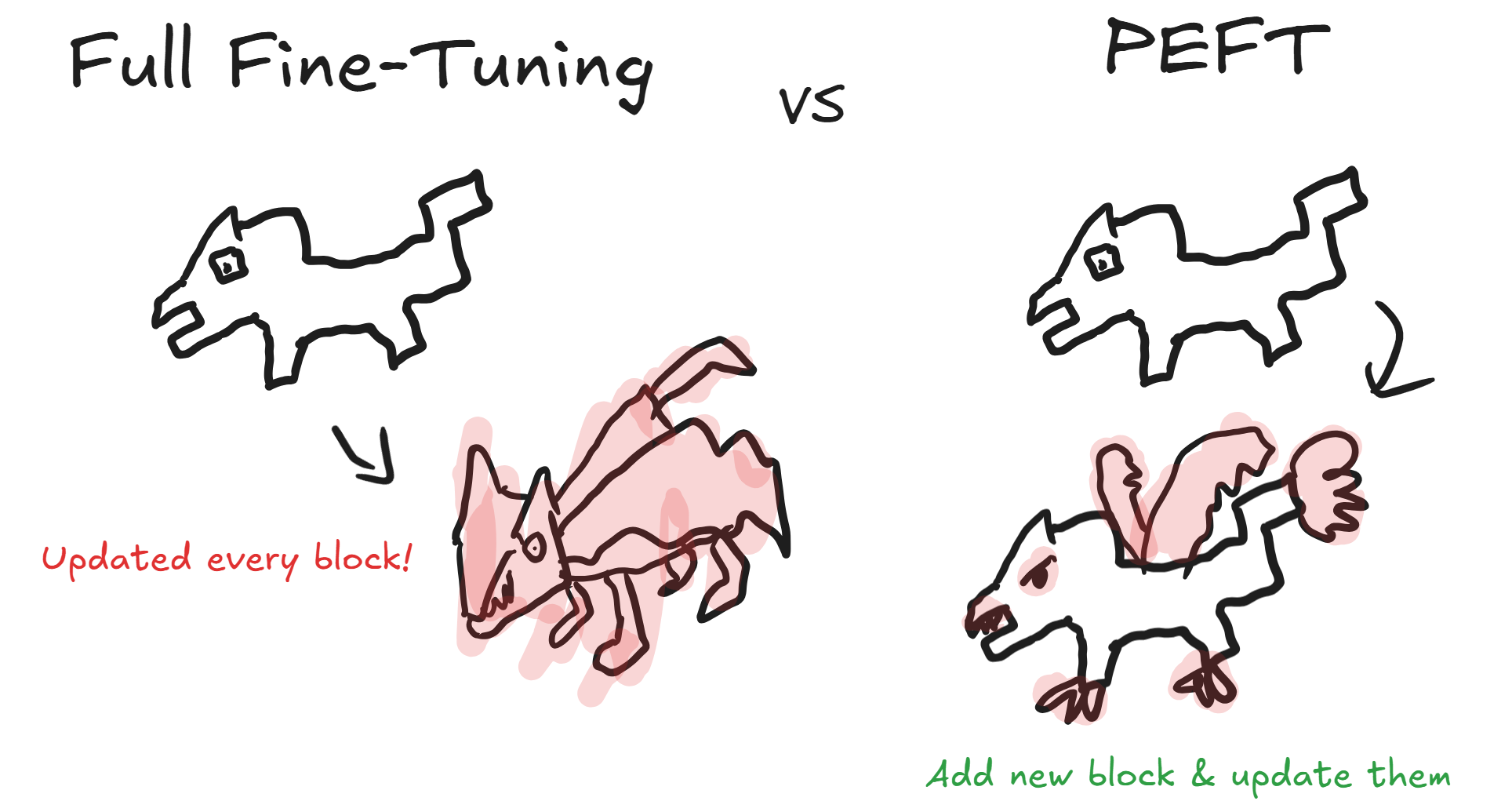
To put it simply with an analogy, Full Fine-Tuning is like replacing all the blocks in a finished Lego creation with slightly better ones to improve its look. PEFT, on the other hand, is like improving the Lego creation by replacing only some of the existing blocks or by adding new blocks on top of the old ones.
Full Fine-Tuning has the advantage that the model can be made to perform our intended task more accurately. However, this began to change with the advent of the Large Language Model era. Trying to tune a model with around 1.5 billion parameters required significant complexity and time, leading to reduced efficiency. Consequently, the PEFT methodology began to rise, suggesting that tuning or adding only a subset of parameters was a better way to achieve good performance on LLMs with less time and cost.
As the importance of PEFT became more prominent, in 2021, a research team from Microsoft proposed a new PEFT mechanism called LoRA in their paper, LoRA: Low-Rank Adaptation of Large Language Models.
LoRA
LoRA (Low-Rank Adaptation)'s core objective is to find low-rank representations within the original weight matrices of a pre-trained model.
What does "low-rank" mean here? To understand this, we need to take a brief detour into the world of linear algebra.
For example, consider the following 3x3 matrix:
[ 1, 2, 3 ]
[ 2, 4, 6 ]
[ 3, 6, 9 ]
In this matrix, each subsequent row is simply a multiple of the first row. For instance, the second row [ 2, 4, 6 ] is just the first row's values multiplied by 2.
Therefore, we can define the most representative row that describes this matrix as [ 1, 2, 3 ]. This matrix is said to have a low rank.
Conversely, if all rows and columns of a matrix contain completely independent information, that matrix is called 'Full-Rank'. A full-rank matrix can be thought of as being informationally dense, with no room for compression.
LoRA applies this principle to the model's weight matrices. The idea is that a model's large weight matrix can be effectively represented by low-rank matrices. Therefore, the goal is to find, mimic, and train these low-rank matrices to update the weights.
The image above illustrates the structure of LoRA.
To achieve PEFT, LoRA freezes all the original weight matrices and creates two new matrices, A and B, that mimic the original weight matrix, and only these new matrices are trained.
For example, if an original weight matrix has dimensions d x k, the new weight matrices A and B will have dimensions d x r and r x k, respectively. With Full Fine-Tuning, d x k parameters of the original matrix need to be updated. That is, if the weight matrix is 1000 x 1000, one million weights must be updated. However, with LoRA, only (d x r) + (r x k) parameters from matrices A and B need to be trained. If the original matrix is 1000 x 1000, and A and B are 1000 x r and r x 1000, then only a total of 2000r parameters need to be updated.
Here, r is the rank mentioned earlier, a hyperparameter that the user must set. It is typically set to powers of 2, such as 2, 4, 8, 16, 32, 64.... A smaller r means the model works with a lower-rank approximation to represent the full matrix, leading to higher information compression. A larger r allows for a higher-rank representation, preserving more information during compression.
This is possible thanks to the multiplication of matrices. The LoRA weight matrices of size d x r and r x k can be multiplied to produce a single d x k matrix. This means it becomes the same size as the original weight matrix and can act as if it's mimicking it. LoRA assumes that this newly created matrix will be very close to the desired 'change' ΔW.
The training and inference process for LoRA to achieve this is as follows:
- Training: The input is passed through both the original weight matrix and the two new LoRA weight matrices separately. The outputs from the original matrix and the new matrices are then summed to produce the final model output. When a loss occurs, backpropagation is applied only to the LoRA weight matrices.
- Inference: Similar to training, the input is passed through both the original and the LoRA weight matrices. The outputs are then summed to determine the final model output.
In summary, LoRA is a training method that aims to boost a model's fine-tuning performance by training new, relatively information-compressed matrices A and B that mimic a specific weight matrix, making it behave as if the original weights were being updated.
Project Retrospective
So far, I've covered the structure and mechanisms of GPT-2 and the LoRA fine-tuning technique, which were the topics I studied most keenly during this project.
I learned a lot once again while working on this project, and I'd like to share a few reflections.
First, to share the results: the news fine-tuning was successful, but the attempt to fine-tune the Joker's speech patterns did not yield significant results.
I believe the reason for this lies in the pros and cons of LoRA.
First, the advantage of LoRA is that it allows for fast, easy, and efficient fine-tuning. This is especially appealing for those who do not have access to vast computational resources.
Also, when I was fine-tuning, the number of parameters I trained was:
trainable params: 147,456 || all params: 124,588,032 || trainable%: 0.1184
As you can see, it was about 147,000, which is roughly 0.11% of the 1.5 billion parameters of the original GPT-2 1.5B model. This means I trained 99.89% fewer parameters than I would have with Full Fine-Tuning.
However, the disadvantages of LoRA were just as clear.
When I was training the model on the news dataset, I had about 2000 training samples and 500 test samples. I ran it for 5 epochs, and I could see the loss decreasing noticeably as the epochs progressed.
But to train a GPT-2 that mimics the Joker's speech, I needed a dataset of his lines, which was not easy to find. I ended up generating about 500 lines myself using LMM Gemini-2.5-Pro.
This was not enough data to train the model properly, and ultimately, the training did not proceed smoothly.
Of course, this is less a problem with the LoRA model itself and more about the lack of training data, a common issue in all of AI.
However, LoRA's shortcomings also influenced the project. A 'speech pattern' is not an easily discernible pattern. The Joker's speech is particularly tricky because it's somewhat peculiar yet adheres to a correct general sentence structure.
For cases like this, I came to think that Full Fine-Tuning, which fine-tunes all the model's parameters, might be a better approach. Because LoRA learns fewer parameters by mimicking a subset of them, it can struggle to properly learn complex patterns or domain-specific nuances.
In the process, however, I did try to improve the model's performance even slightly through efforts like using the Priming Technique.
In the end, this project was like an experience-doubling event for me. I had a successful fine-tuning experience with the news dataset, and I also gained experience with a failed fine-tuning attempt by directly confronting the limitations of LoRA, which I had only thought of as being good.
Conclusion
It has been a long journey from Seq2Seq Attention and Self-Attention to fine-tuning GPT-2. Experiencing the progress of the NLP field firsthand through this learning process made it all the more enjoyable and exciting.
In fact, as of this writing in October 2025, several LLMs are already available for us to learn from, such as the new open-source GPT-OSS from OpenAI, Grok 2.5, and Deepseek R1.
This means I have to keep learning... haha.
Anyway, it took about a month to learn everything from the attention mechanism to GPT-2 fine-tuning, and it feels like it was a truly productive month after a long time. This project ends here, but I will continue to learn about the NLP field and strive to learn about many other areas of artificial intelligence as well.