
GPT and BERT: The Two Pillars of the Transformer Model
Overview
In our daily lives, there is one AI that everyone, regardless of age or gender, knows: GPT, Generative Pre-trained Model, also known as ChatGPT. ChatGPT is a deep learning model launched by OpenAI, and as of September 27, 2025, when this article is being written, many people know, hear about, and use it.
As a teenager in my late teens at the time of writing, I am exposed to an environment where I frequently encounter new technologies. Naturally, I have seen ChatGPT as an artificial intelligence since 2021-2022. At that time, I remember perceiving it as merely a toy for simple banter, similar to existing AI services in Korea like 'Simsimi' or 'Iruda'.
However, starting in 2023, as school teachers began mentioning ChatGPT, and over time, by 2024 and currently in 2025, seeing it known and used by news outlets, parents, and even quite elderly people, was truly fascinating.
When ChatGPT is frequently discussed, various terms are used, such as 'chatbot', 'generative AI', and 'conversational AI'. In fact, the accurate term is the Transformer model we covered in the previous post, specifically a Transformer-based model.
Since the emergence of the Transformer model in 2017, numerous models for NLP have appeared, leading to exponential growth year by year in 2018 and 2019. The key models that emerged then were GPT (Generative Pre-trained Model) and BERT (Bidirectional Encoder Representations from Transformers).
Therefore, in today's post, we will explore what the GPT and BERT models are and examine their structures together.
The Dawn of Pre-training, Fine-tuning, and Transfer Learning
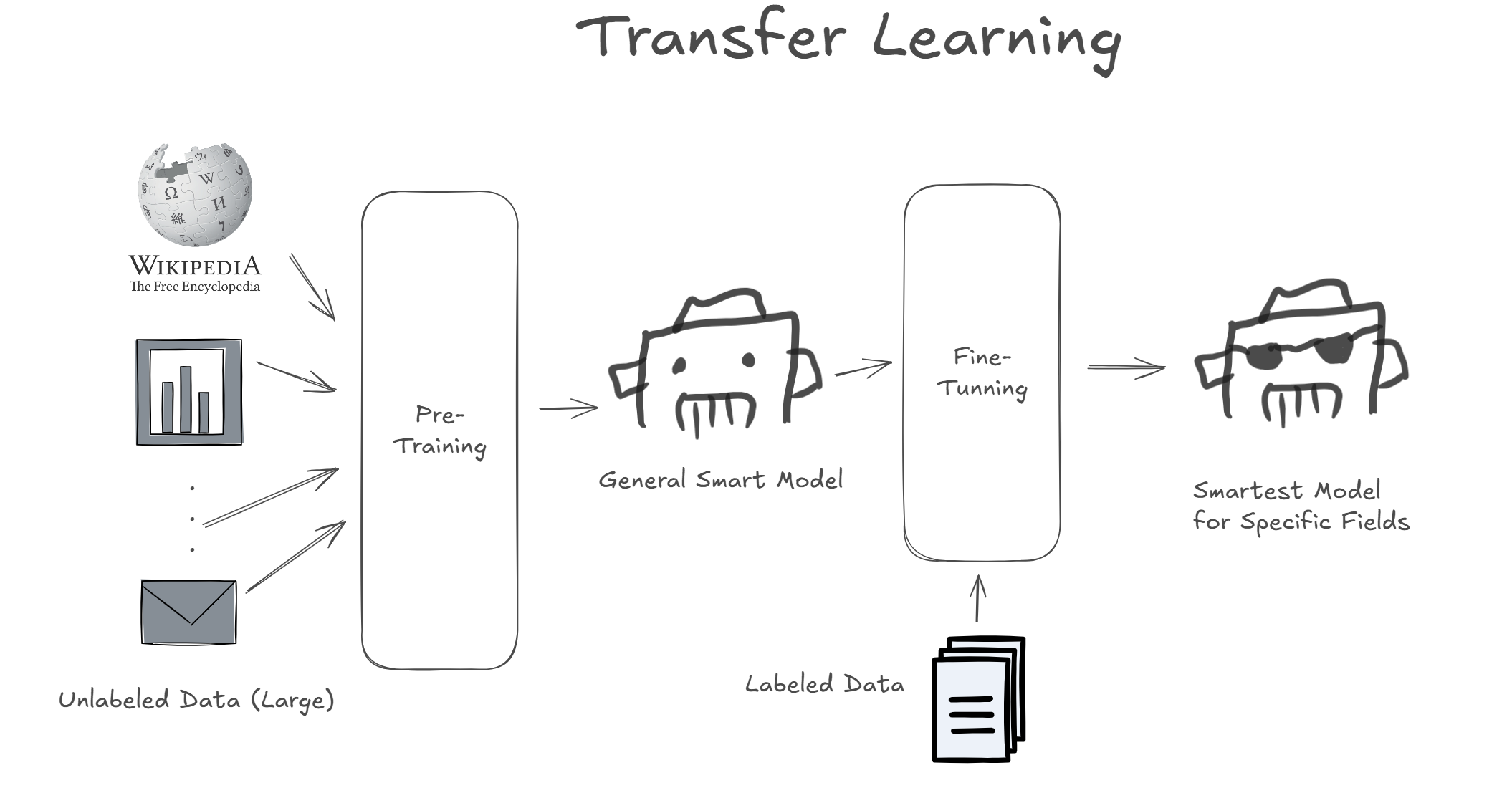
Before delving into GPT and BERT, it's easier to understand if we know a few characteristics about them. GPT and BERT introduced a new perspective to the NLP field through three paradigms: Pre-training, Fine-tuning, and Transfer Learning.
Let's look at each one.
Pre-training
Pre-training is a technique where a model is trained not for a specific purpose using supervised learning with labeled data, but by using unsupervised learning on a vast amount of unlabeled data. This was a contrasting approach to the 'complete training' method (training a model from scratch for a specific purpose), which had been the dominant trend in deep learning until then.
The model is trained to predict using a wealth of data available on the internet, such as Wikipedia and news articles. This usually consumes enormous computing resources, making it feasible only at the corporate or research institution level. It was at this point that the concept of LLM (Large-Language-Model), a language model trained on a massive amount of data, emerged.
Fine-tuning
Fine-tuning is a method of training a pre-trained model using supervised learning on a smaller, labeled dataset to solve a specific problem (e.g., classification, sentiment analysis, sentence generation).
A model undergoing fine-tuning has already learned from a vast amount of data and generally performs well across various domains. Therefore, by performing supervised learning with a small dataset specific to a certain field, a model tailored to solve that particular problem is created.
Transfer Learning
Transfer Learning refers to the entire process of pre-training a deep learning model and then fine-tuning it to create a specialized model for solving problems in a specific field.
This concept of transfer learning was proposed by Dr. Geoffrey E. Hinton in the paper "Deep Belief Networks" and began to be actively used in the NLP field around 2018-2019.
GPT and BERT actively utilized this transfer learning, and many subsequent models in NLP also began to adopt it.
GPT and BERT: Encoder vs. Decoder
GPT and BERT, rooted in the fundamental Transformer model, evolved into slightly different model structures.

In the Transformer model, the encoder and decoder can be divided into the following roles:
- Encoder: Strives to understand sentence information as much as possible by compressing the relationships between all words in a sentence.
- Decoder: Analyzes word relationships in a sentence to generate text and extracts the next word with the highest probability. The encoder's information is needed in this process.
In short, the encoder focuses on 'information summarization', while the decoder focuses on 'probability estimation through information'. Here, GPT and BERT adopted model structures that maximize the advantages of one side by completely removing the other, specifically leveraging the characteristics of their respective encoders and decoders.
GPT removed the encoder, emphasizing the decoder's role in sentence generation, while BERT removed the decoder, maximizing the encoder's strength in analyzing relationships and extracting context within a sentence.
Let's now examine how GPT and BERT were configured to achieve excellent performance by removing their respective encoders and decoders.
GPT, The Master of Probability Games: Decoder 🎰
GPT was first introduced in a 2018 paper titled "Improving Language Understanding by Generative Pre-Training" by OpenAI, then a non-profit research organization.
As mentioned earlier, in this paper, researchers including Alec Radford proposed a method of training a large-scale text dataset using unsupervised learning and then fine-tuning it for specific tasks. This opened up the possibility of solving various natural language processing problems with a single, general-purpose model.
This GPT was designed with a structure that excludes the encoder and maximizes the generative capabilities of the decoder. Let's take a closer look at the GPT's structure.
GPT Structure

The left side of the image shows the overall structure of GPT, while the right side illustrates the detailed structure of the Transformer Block Layer. This may look complex, but it actually has a simple structure. Let's examine it step by step.
Input Embedding + Positional Embedding
As is common in all Transformer models, this involves separating a specific sequence into tokens that a computer can understand, vectorizing the separated tokens, and then performing Positional Encoding to allow the model to recognize positional information.
After this step, the sequence is output as vector values that contain positional information, making it easier for the computer to understand its meaning.
Dropout
After generating these vectors, some of their values are randomly set to 0 through Dropout. The reason for performing Dropout is to randomly make some dimensions of the vector meaningless, thereby preventing the model from overfitting.

Although the Transformer Block applies Dropout to the vector at the end, the vectors input to the Transformer model initially do not pass through this specific layer, which is why Dropout is applied separately at this stage.
A question here: What if a vector dimension carrying important information is dropped due to Dropout? In fact, this is precisely the purpose and intention that Dropout induces.
Let's consider a hypothetical situation. You are a teacher in a classroom with many students. Among these students, there are a few who are exceptionally good at studying (vector dimensions with a lot of information). You give math problems to the students, reward those who solve them, and the rewarded students receive "smart candy" that makes them even smarter. If this process is repeated, the already smart students will continue to receive candy, and the rewards will become biased.
To prevent this, one rule can be added: randomly selecting a few students to skip solving problems this round. This is precisely what Dropout is.
Therefore, Dropout prevents overfitting through this mechanism, enabling the model to achieve stable and average performance. Furthermore, Dropout is applied only during training, ensuring that all vector dimensions maintain their meaning during the inference phase, thereby returning optimal results.
Transformer Block
In the GPT structure, the Transformer Block is broadly divided into two parts:
- Masked Self-Attention Layer
- Feed Forward Neural Network
These two layers are actually quite similar to the decoder of the original Transformer model, with a few slight differences. Let's examine each one.
First, the Masked Self-Attention Layer is a Self-Attention structure that applies Masking, which we are familiar with. By applying masking, the model avoids peeking at information from the token that needs to be generated until the end of the sentence during training. Instead, it focuses on compressing and weighting information up to the token that needs to be generated, thus training the weight matrices (Q, K, V).
The final token generated by these learned weight matrices is trained to maximize the information needed to generate the next token. Furthermore, the Multi-Head structure maximizes the efficiency and accuracy of learning.
The generated vector undergoes Dropout, followed by Add & Norm for residual learning and normalization, and then is passed to the next FFN layer.
Next, in the Feed Forward Neural Network, based on the contextual information obtained through attention, each word's meaning is individually processed and transformed more deeply. The first Linear layer expands the dimension, and the GeLU activation function creates a non-linear output, after which the second Linear layer reduces the dimension back to the original vector level.
Afterward, Dropout is performed again, and Add & Norm is applied for residual learning and normalization before being passed to the next layer.
The internal structure of the Transformer Block is as described, and in the case of GPT-1, approximately 12 Transformer Blocks are stacked.
LayerNorm
Normalizes the vectors that have passed through several Transformer Blocks to prevent them from leaning towards a specific range, thereby stabilizing the training process.
Linear + Softmax

In Softmax, the processed vector's dimensions are expanded to the number of all words known to the model. Then, in the final Linear layer, the resulting values are converted into probabilities to calculate the likelihood of each word being correct. The sum of probabilities for all words is made to be 1, and the word with the highest probability is predicted as the next word.
The generated word is then included in the sequence generated so far and used as input for predicting the next word.
GPT Summary
By removing the encoder, GPT enabled efficient sentence generation. Through the Masked Self-Attention technique in the Transformer Block, it performed optimized training, demonstrating excellent performance even during inference.
GPT is primarily fine-tuned for use in areas such as chatbots, content creation, text summarization, and machine translation.
However, due to the decoder's characteristic of generating words in a unidirectional Left-to-Right manner, there can be limitations in comprehending overall sentence context.
BERT, The Perceptive Encoder 👀
BERT was a model released in 2019 in a paper titled "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" authored by researchers from the Google AI Language team.
As its name 'Bidirectional Encoder Representations from Transformers' suggests, BERT is a model for bidirectional contextual learning, based on the Transformer encoder's structure.
While GPT excels at sentence generation, it inevitably faces limitations in context understanding due to its masking structure.
Because of masking, GPT must infer by progressively revealing data from Left to Right, one by one. This means that information further down the sentence is masked and hidden, so it can only grasp context based on the aggregate information available up to the current point. This approach can have limitations.
For example, suppose we use a GPT model to understand the context of the sentence, "The cat sat on the TV". Due to masking, the data would be progressively revealed in sequences like "The cat", "The cat sat", and so on. However, understanding the full context based only on "The cat sat on" is difficult. This is a limitation of GPT's context awareness; it can only refer to Left-side contextual information. Nevertheless, Self-Attention can cover this to some extent, allowing it to predict context by leveraging Left-side information as much as possible.
Ultimately, BERT adopted an encoder that uses Self-Attention without such directional restrictions (i.e., without masking), thereby becoming a model that maximizes performance in context understanding.
Now, let's examine the structure of BERT.
BERT Structure

BERT is primarily categorized into two sizes: BERT Base and BERT Large.
BERT Base and Large simply differ in the number of BERT Layers stacked, which include Multi-Head Attention and Feed Forward layers. BERT Base uses 12 BERT Layers, resulting in 1.1 million parameters, while BERT Large uses 24 BERT Layers, leading to 3.4 million parameters.
A BERT Layer is essentially identical to the Transformer's encoder, consisting of a Self-Attention Block performed with Multi-Head Attention, an FFN, and Add & Norm for residual learning and normalization.
However, BERT's distinguishing feature is that its operational mode changes depending on the input and output data. There are two main operational modes for pre-trained BERT:
- MLM (Masked Language Model)
- NSP (Next Sentence Prediction)
Let's examine BERT's operation process according to these two modes.
MLM (Masked Language Model)
MLM (Masked Language Model) is a mode of operation where BERT uses a portion of a sentence to find specific masked tokens through bidirectional context.
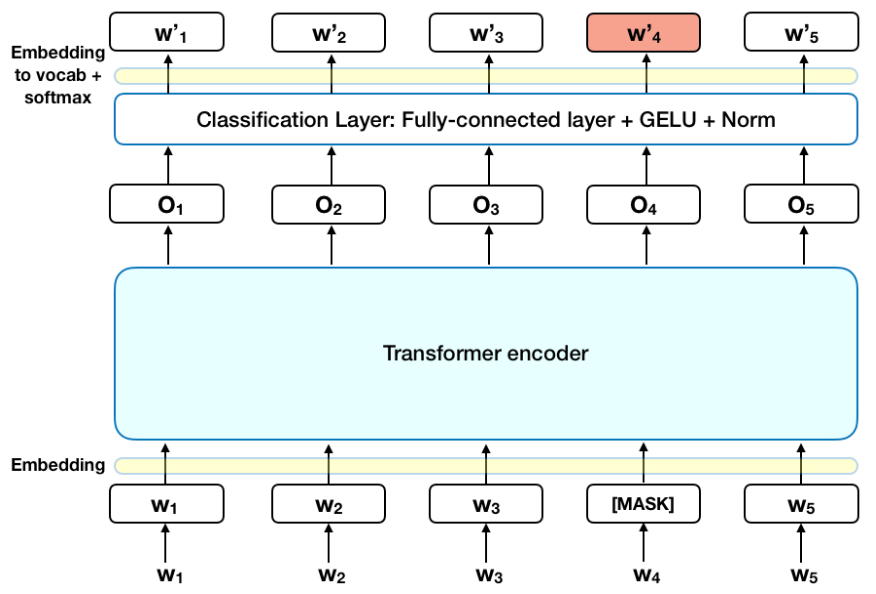
This image shows the BERT model being used with MLM. W1 to W5 represent tokens, and W4 is masked as [MASK]. To find this masked token [MASK], BERT performs Self-Attention to incorporate bidirectional context and ultimately updates its weights.
When trained in this manner, BERT, when a specific part is [MASK]ed, selects and outputs the token with the highest similarity through its learned weights.
I also tried MLM using the multilingual BERT model, [bert-base-multilingual-cased].
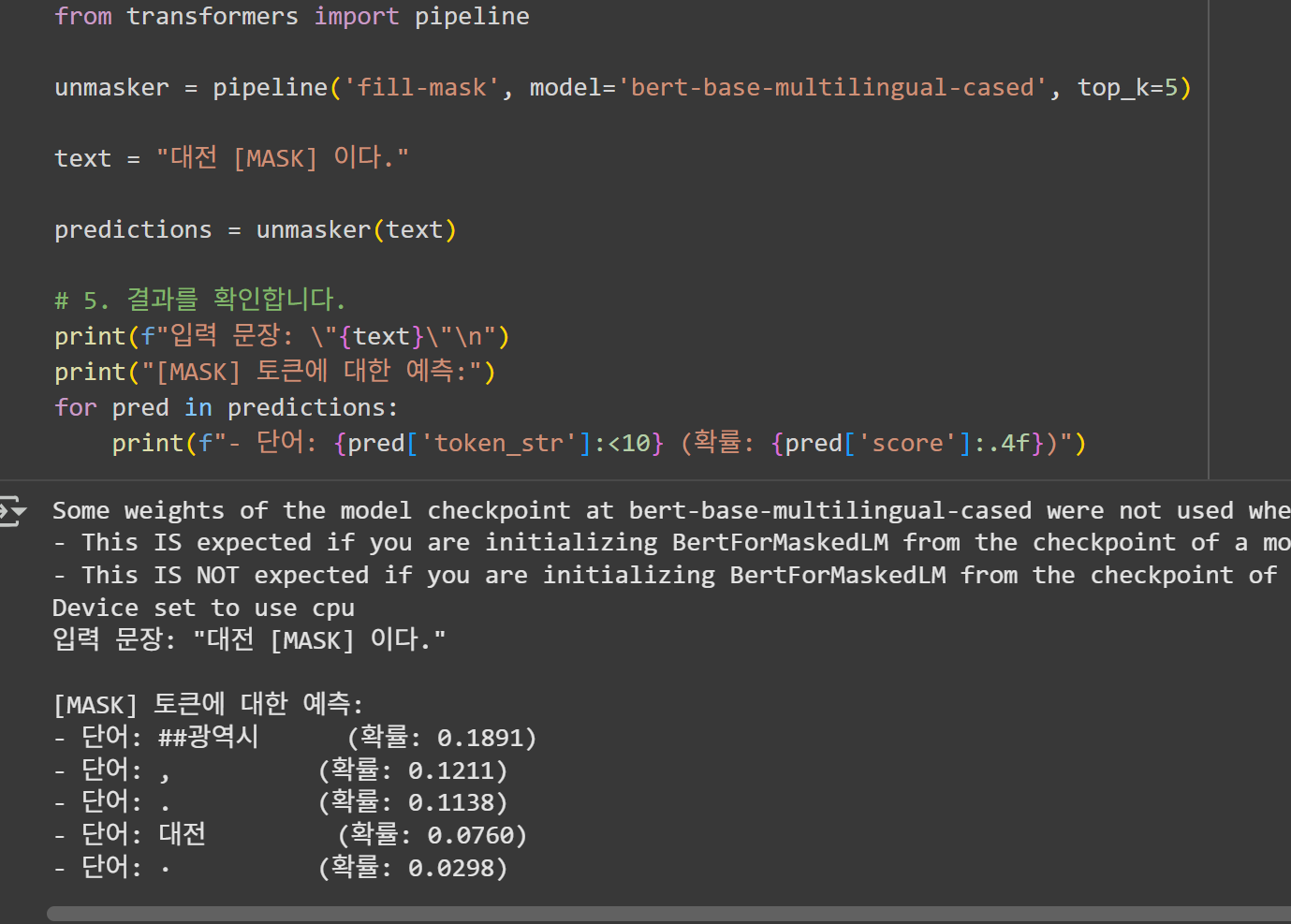
As shown, '##광역시' (here, '##' indicates a phenomenon caused by BERT's embedding model, meaning a token that can follow various city tokens like Seoul, Busan, etc.) associated with Daejeon is predicted with the highest probability.
NSP (Next Sentence Prediction)
NSP (Next Sentence Prediction) is a mode where, given two sentences, BERT classifies whether the two sentences are connected (IsNext) or are separate, unrelated sentences (IsNotNext).

The image above shows the BERT model inferring whether two sentences are connected or not.
A [CLS] token is added at the beginning of the first sentence, and a [SEP] token is inserted at the point where the first sentence ends and the second sentence begins, allowing BERT to distinguish between the two sentences.
BERT uses Attention to determine if the two sentences are related and finally outputs whether the two sentences are connected (IsNext) or are separate, unrelated sentences (IsNotNext) based on the final output vector of the [CLS] token.
In addition, for each token for NSP, we add segational Embedding to each token, Segement Embedding distinguishes the tokens by segment token when we proceed with self -attion as a token to distinguish whether each token is the first sentence or the second sentence.
BERT Summary
BERT actively utilized the Self-Attention of the Transformer model's encoder to leverage bidirectional context, achieving high performance in both predicting specific masked words in a sentence and predicting the relationship between two sentences.
This BERT model can be specialized for various fields through fine-tuning.
BERT is particularly widely used in areas such as context understanding, content summarization, and text classification.
GPT and BERT: How Have They Evolved Today?
We have now learned about GPT and BERT. Each maximized the advantages of the decoder and encoder, respectively, by removing the other. However, GPT encountered limitations in context understanding, and BERT faced limitations in sentence generation.
But how have GPT and BERT evolved, given that it's 2025 as I write this? In fact, we already know the answer. We now ask the latest model, GPT-5, to perform tasks like context understanding, content summarization, and text classification—things that the original GPT-1 would never have been able to accomplish. How did this become possible?
The paradigm completely shifted with the launch of GPT-3 in 2020. GPT-3, utilizing 175 billion parameters, proved that it could reach BERT-level comprehension. Furthermore, it demonstrated that with proper prompt engineering, specific tasks could be handled at an expert level even without fine-tuning.
Thus, LLMs (Large-Language-Models) trained with massive parameters like GPT-3 proved their ability to perform general tasks in NLP. While BERT is still used in specific fields, GPT has become a model that has largely overcome its initial limitations.
Conclusion
In this post, we explored the structures and operational methods of Encoder-Only model BERT and Decoder-Only model GPT, with the Transformer at their forefront.
The implementation method of maximizing the strengths of the decoder and encoder, respectively, was particularly fascinating. It reaffirmed that the Transformer was indeed an innovative and historically significant model.
Furthermore, it was an interesting experience to learn about the basic structure and origin of the GPT model, which I use, even if it's not GPT-5.
In the next post, we will briefly analyze GPT-2, which returned with an increased number of parameters (not GPT-1), and even try fine-tuning it.
References
- Introduction to Generative Pre-trained Transformer (GPT) | GeeksforGeeks
- Encoder-Only Transformers (like BERT) for RAG, Clearly Explained!!! | StatQuest with Josh Starmer youtube channel
- [딥러닝 자연어처리] BERT 이해하기 | Minsuk Heo 허민석 youtube channel
- BERT와 GPT의 개요 | 서울시립대학교 DS플러스 사업단 youtube channel
- Materials learned from a surprisingly large number of LMMs and the internet.