
Attention 그리고 Self-Attention. 왜 이것들이 중요한가?
개요
저는 요즘 NLP(Natural Language Processing) 분야를 관심있게 공부하고 있습니다. 이것은 매우 재미있고 흥미로우며, 새롭게 느껴집니다. 1년전만 해도 저는 ChatGPT, Gemini 그리고 Grok과 같은 LLM(Large Language Model)들이 내부적으로는 어떻게 동작하는지 정말하나도 몰랐습니다. 단순히 사용자의 입력을 LLM이 받으면, LLM이 내부적으로 확률적으로 단어를 선택하고, 선택된 단어가 최종 출력으로 사용자에게 전달되는 구조라는 정도까지가 제가 알고있는 지식의 한계였습니다.
하지만 NLP라는 분야에 관심있게 빠진 이후부터는 AI의 기초인 머신러닝, Neural Network, MLP, CNN 그리고 RNN 까지 하나하나 학습하고 있습니다. 최근에는 RNN에 대해서 공부하고있으며, 제가 관심있는 분야인 NLP를 위해 Attetion과 Self-Attetion 그리고 Transformer 모델에 대해서 역시 공부하고 있습니다.
오늘 post에서는 Attention과 Self-Attention에 대해 제가 이해한 내용을 바탕으로 정리하고, 이것들이 어떤 역사를 가지고 NLP 분야에서 중요해지게 되었는지까지 이야기 해보려 합니다.
Attention의 등장배경: Seq2Seq의 한계
먼저, 우리가 알아야 할 것은 "Attention이 어떻게 등장하게 되었는가?" 입니다.
Attention Mechanism의 등장은 기계 번역 문제를 해결하기 위해 제안된 RNN(Recurrent Neural Network) 기반 모델중 하나인 Seq2Seq(Sequance-to-Seqaunce) 모델로 부터 등장하게 되었습니다.
당시 Seq2Seq모델은 Encoder-Decoder 구조를 가지는 모델이였는데, 다음과 같은 한계점들을 지니고 있었습니다.
-
고정 길이 문맥 벡터 (Fixed-length Context Vector): 인코더는 입력 문장의 모든 정보를 고정된 크기의 벡터 하나로 압축해야 했습니다. 이는 문장이 길어질수록 정보 손실이 발생하여 번역의 질이 떨어지는 '병목 현상(bottleneck)'을 야기했습니다.
-
장기 의존성 문제 (Long-term Dependency Problem): RNN의 고질적인 문제로, 문장의 시작 부분에 있는 중요한 정보가 뒤로 갈수록 희미해져 제대로 전달되지 못하는 한계가 있었습니다.
결국 쉽게 말해서 RNN의 특성상 이전 정보의 중요성이 문맥이 증가함에 따라서 저하될 수 밖에 없는 구조였고, 이에 따라 모델의 직접적인 성능 이슈가 생겼다는 점이였습니다.

이것을 쉽게 비유하자면, 정확한 예시는 아니지만 우리가 평소 소문이 이상하게 번져나가는 상황을 대인관계에서 경험해보신 적이 있으실 텐데요, 소문이 사람을 타고타고 와전되어서 초기와는 완전 다른 소문이 된것을 본적이 있으실 겁니다. Seq2Seq 모델도 그런 한계점을 가졌다고 생각해보면 쉽게 떠올릴 수 있습니다.
따라서 많은 연구자들이 이러한 문제점을 해결하기 위해 노력했고, 2015년, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio 등 몬트리올 대학교 연구진은 "Neural Machine Translation by Jointly Learning to Align and Translate" 라는 기념비적인 논문을 발표합니다. 이 논문에서 처음으로 'Attention'이라는 개념이 제안되었습니다.
Attention의 등장, Context Vector의 발전
Attention이 처음 등장했을때 개념은 다음과 같습니다. "Decoder의 각 time step에서 단어를 생성할 때, 입력(Encoder) Sequance 특정 부분에 더욱 '집중(attend)' 하여 생성된 Context Vector를 참고하여 생성" 이것이 논문에서 처음으로 제안된 Attention의 개념이라고 할 수 있습니다.
즉, Attention이 적용되지 않은 RNN 모델은 Context Vector가 초기에 한번만 생성되고, 출력 Layer에서 출력 시퀀스를 생성해낼 때는 문맥 손실 가능성이 있는 Context Vector만을 참고하여 생성해야하지만, Attention 적용 이후부터는 특정 토큰을 생성해야 한다면, 그 토큰과 관련된 정보를 조금 더 잘 나타내는 Context Vector를 참고하기에 성능이 올라간다는 이야기 입니다.
이를 그림으로 표현하면 다음과 같습니다.
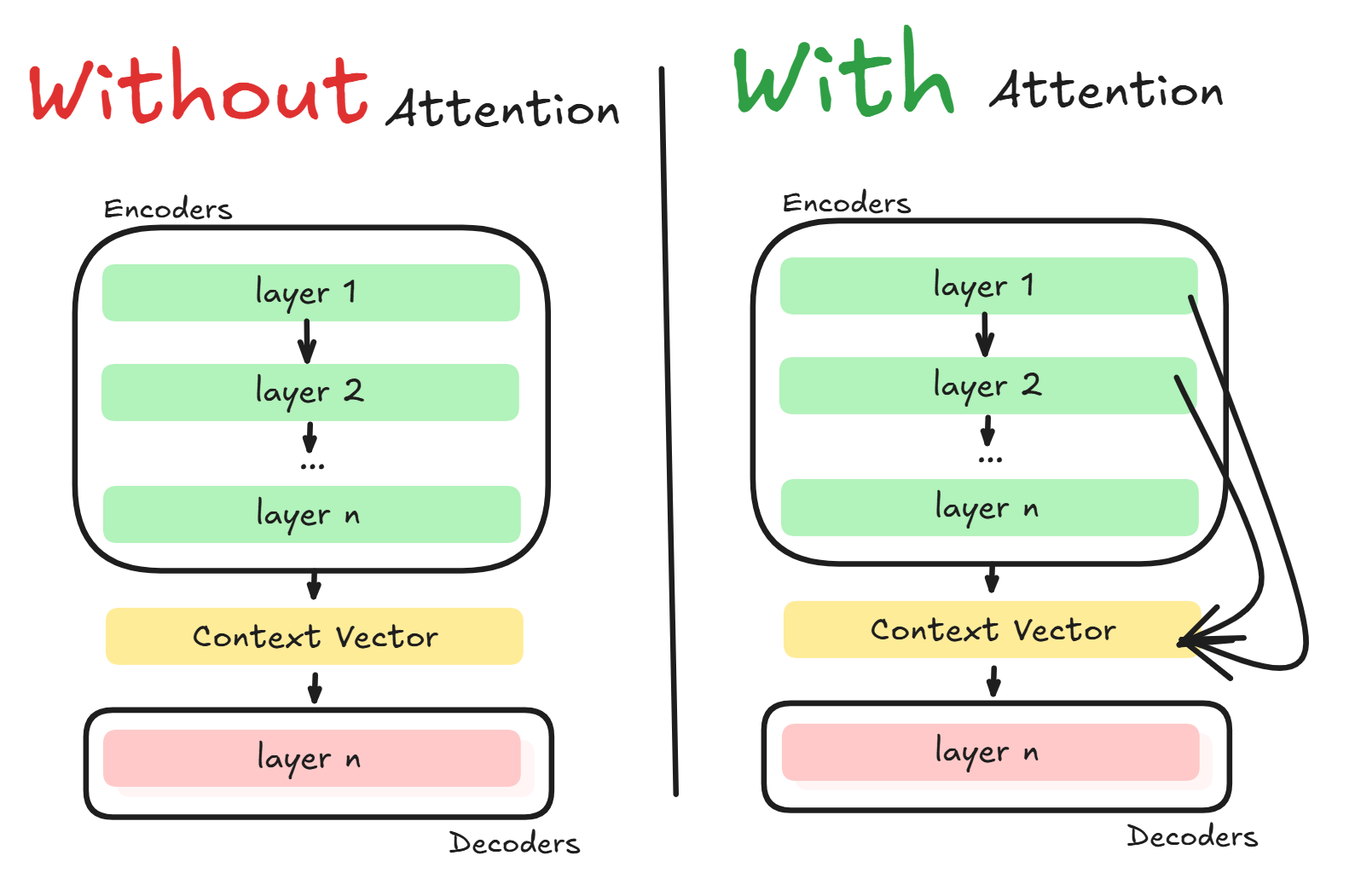
매우 간단하게 표현한 그림이라 정확하지는 않지만, 대략 전체적인 큰 틀에서 Attention을 사용하지 않았을 때 정보가 Context Vector에 담기는 과정과 Attention을 사용했을때 정보가 담기는 과정에 차이가 있다는 것을 보여드리고 싶었습니다.
그렇다면 Attention이 동작하는 과정을 조금 더 자세히 알아봅시다.
Attention의 동작 과정
Attention의 주요 동작 과정을 지금부터 살펴보기 위해, 먼저 우리는 Attention을 수행하기 위한 핵심 구성요소인 Q(Query), K(Key) 그리고 V(Value) 에 대해서 알아봐야합니다.
Attention의 핵심 구성요소 Q, K, V
-
Q(Query): Q(Query)는 디코더에서 현재 시점에서 시퀀스를 생성하기 위해 참조하고 있는 토큰, 즉 time step hidden state로, Q(Query)를 통해 인코더에 어떤 토큰이 다음 토큰 생성을 위해 필요한 정보를 가지고 있는지 질문합니다.
예를 들어, "나는 너를 사랑해"라는 문장을 영어로 번역한다고 가정해봅시다. 우리가 현재 "I" 까지만 번역했고, 다음 정답 단어인 "love"를 생성하기 위해서는, "I"라는 단어가 어떤 단어와 관련있는지 살펴봐야 합니다. 따라서 이때 Q(Query)는 "I"가 되고(실제로는 'I'에 Wq(쿼리 가중치)를 곱한 값이 Q가 됩니다.), "I는 어떤 단어와 연관있니?"라는 정보를 전달하게됩니다. -
K(Key): K(Key)는 인코더가 생성한 토큰(hidden state)들로, Q(Query)를 통해 찾아야 하는 대상이기도 합니다. 보통 어떠한 Q(Query)와 K(Key)가 관련도가 높다고 하면, 두 벡터를 내적했을때 결과 스칼라의 값(이를 Attention Score 라고도 합니다.)이 높게 나타납니다.
이전 예시에서 "I" 다음 단어를 생성하기 위해 "I"를 Q(Query)로써 인코더 단어들과 비교한다고 했는데, 여기서 인코더 단어들이 K(Key)에 해당하고, 그 중 "I"와 관심(attend)을 보이는 K(Key)는 아마도 "사랑"(인코더 단어이므로 한글.)일 것 입니다. -
V(Value): V(Value)는 Q와 K의 연관성을 나타내는 값으로, 실제로 일반적인 Attention에서는 K(Key)와 V(Value)가 동일하기도 합니다. V(Value)값을 통해 Context Vector에 어텐션 스코어가 적용된 Q(Query)를 위한 새로운 정보를 담는데 사용합니다.
이전 예시에서 "I"(Q)와 "사랑"(K)이 높은 관심도(Attention Score)를 가지는 것을 우리는 확인했습니다. 따라서 이때 Context Vector에는 해당 정보가 포함될 것 이고, 마침내 모델은 다음 단어를 Context Vector를 참고해 "사랑"이라는 단어를 영어로 번역한 "love"로 예측하게 됩니다.
Q, K, V에 대해서 간단히 살펴보면서 어느정도 Attention의 동작 과정도 간략히 설명 드린 것 같은데요. 다시 한번 Attention의 동작 과정을 복습해보겠습니다.
Attention 동작 과정
- Encoder에서 입력 토큰들을 K이자 V로 변환.: Encoder는 전체 입력 시퀀스를 읽어들여, 각 입력 요소에 대한 정보 벡터(Hidden State)의 묶음을 생성합니다. 이 정보 벡터 묶음은 이후 디코더가 참고할 Keys(참조 목록)와 Values(실제 정보)의 역할을 합니다.
- Decoder 동적 정보 활용을 통해 출력 요소 생성: 아래 과정들이 출력 요소(토큰)을 하나 생성할 때 마다 반복됩니다.
-
Q(Query) 생성: 디코더는 현재까지 생성된 출력과 자신의 내부 상태를 바탕으로, 다음에 필요한 정보가 무엇인지에 대한 Q(Query) 를 생성합니다.
-
스코어 계산: 생성된 Query를 인코더의 모든 Keys와 비교하여, 현재 Query와의 관련도를 나타내는 '어텐션 스코어'를 각각 계산합니다.
-
가중치 변환: 계산된 스코어들을 소프트맥스 함수를 이용해 총합이 1인 어텐션 가중치(Attention Weights) 로 변환합니다. 이 가중치는 입력 요소 각각에 대한 '집중도' 또는 '중요도'를 나타냅니다.
-
Context Vector 생성: 이 어텐션 가중치를 인코더의 Values에 곱한 뒤 모두 더하여, 현재 시점에 최적화된 단일 Context Vector(문맥 벡터) 를 만듭니다. 이 벡터는 '중요한 정보는 강조하고, 불필요한 정보는 무시'한 결과물입니다.
-
최종 예측: 디코더는 자신의 현재 상태와 이 맞춤형 Context Vector를 함께 고려하여, 출력 시퀀스의 다음 요소를 최종적으로 예측합니다.
-
이제 Attention이 어떻게 동작하는지에 대한 기본적인 지식은 어느정도 살펴본 것 같습니다. 하지만 이러한 Attention도 사실 RNN의 모든 문제를 해결하지는 못했습니다. 바로 RNN의 근본적인 한계 때문인데요. RNN이 어떤 한계를 가졌고, 이를 극복하기 위해 Attention은 어느 방향으로 나아갔는지 알아보겠습니다.
Attention, RNN의 한계에 부딪히다: Self-Attention의 등장
Attention은 디코더에서 토큰 생성시 인코더의 존재하는 모든 정보를 살펴봐 관계성이 높은 토큰을 골라서 생성한다고 했습니다. 하지만 우리는 잊지말아야할 것 이 있습니다. 바로 인코더의 존재하는 토큰(K, V)들 또한 역시 RNN의 Long-term Dependency Problem를 내포하고 있는 토큰들이라는 것 입니다.
토큰들은 문맥정보를 이전 hidden state를 참조하여 포함하나, 이것은 RNN의 한계상 문맥이 길어질 수록 이전 정보가 손실될 수 밖에 없습니다.
또한 RNN은 마치 도미노와 같아서, 이전 단어의 문맥을 이해하기 전까지는 다음 단어의 문맥계산을 실행하지 못합니다. 마치 ------> 이렇게 화살표처럼 모델의 계산이 진행되어야 하죠. 이는 현대 인공지능 모델의 학습에 주로 사용되는 GPU(Graphics Processing Unit)의 장점을 살리지 못합니다.
정리하자면 Attention은 두 가지 한계를 가집니다.
- 순차적 계산으로 인한 병렬 처리의 부재
- 여전히 남아있는 장거리 의존성 문제 (Long-term Dependency Problem)
따라서 이러한 Attention의 한계를 뛰어넘기 위해 등장한 새로운 Attention Mechanism이 바로 Self-Attention 입니다.
그렇다면 Self-Attention이 무엇이고 이러한 문제점들을 어떻게 해결했는지 함께 살펴보겠습니다.
Self-Attention: Attention Is All You Need.
Self-Attention이라는 개념은 2017년 구글 연구팀에서 발표한 논문인 "Attention Is All You Need"에서 처음 제안되었습니다.
사실 해당 논문은 RNN의 순차적인 구조를 완전히 제거하기 위한 새로운 모델인 'Transformer' 모델을 소개하기 위하여 발표되었고, 그런 Transformer 모델이 문맥 관계와 attend 관계를 파악하기 위해 사용하는 mechanism이 Self-Attention 입니다.
하지만 Transformer 모델의 거의 대부분의 연산에서 Self-Attention이 사용되기 때문에, Self-Attention 이라는 개념이 없었다면 Transformer라는 모델도 등장하지 않았을 것이라 생각합니다.
어쨌든 Self-Attention은 그렇게 세상에 처음 알려지게 되었으며, Self-Attention은 문장 내의 모든 단어가 다른 모든 단어와 직접 연결되어, 어떤 단어가 서로에게 중요한지를 한 번의 계산으로 파악합니다. 이로써 단어 간의 거리에 상관없이 의존성을 학습하고, 모든 계산을 병렬로 처리할 수 있게 되어 속도와 성능을 동시에 잡는 트랜스포머(Transformer) 아키텍처가 탄생하게 된 것입니다.
이제 Self-Attention의 동작 구조에 대해서 조금 더 깊게 들어가보도록 하겠습니다.
Self-Attention의 동작 구조
Self-Attention은 문장 안의 단어들이 서로에게 질문하고 답하며 스스로 의미를 풍부하게 만드는 과정입니다. 마치 네트워킹 파티에 참석한 사람들이 서로 대화하며 각자의 역할을 명확히 하는 것 처럼 동작합니다.
Self-Attention의 모든 연산은 동시에 병렬적으로 일어나며, 이는 GPU의 효율을 극대화 하도록 설계되었기 때문입니다.
Self-Attention 역시 Attention과 마찬가지로 핵심 구성요소인 Q, K, V가 존재합니다. 하지만 Attention과는 조금 다르게 동작합니다. 살펴보도록 하겠습니다.
Self-Attention의 Q, K, V
먼저, 문장의 각 토큰은 세 가지 다른 역할을 부여받습니다. 각 단어의 기본 벡터(임베딩)에 서로 다른 가중치 행렬(Wq, Wk, Wv)을 곱하여 Q(Query), K(Key), V(Value) 라는 3개의 새로운 벡터를 만들어냅니다. 이 행렬들은 입력 벡터를 서로 다른 의미 공간으로 매핑하여 각기 다른 역할을 수행하게 합니다.
- Q(Query): 생성된 Q(Query) 벡터들은 자신과 연관된 K(Key) 벡터들을 찾기 위한 방향을 가집니다.
- K(Key): 생성된 K(Key) 벡터들은 자신의 특성을 더 잘표현 하기 위한 방향을 가집니다.(Q 벡터들이이 자신과 연관된 K 벡터들을 찾도록)
- V(Value): 생성된 각각의 V(Value) 벡터들은 특정 K 벡터의 실제 정보를 포함하고 있습니다. 이를 통해 Q가 K를 찾아내면 V를 통해 실제 값을 찾도록 합니다.
이렇게 Q, K, V는 Attention과 거의 유사한 역할을 합니다. 이제 실제 동작과정에서 어떻게 이 핵심 구성요소들이 작동하는지 살펴보겠습니다.
Self-Attention의 동작 과정
먼저 Self-Attention의 동작 과정을 알아보기 전에, Self-Attention에서 사용되는 벡터들이 꼭 지켜야하는 규칙이 있는데요, 그것은 바로 벡터가 '위치 정보'를 포함하고 있어야 한다는 점 입니다.
RNN의 경우 순차적으로 문맥과 함께 위치 정보가 포함되며 hidden state가 전달되는 반면, Self-Attention은 Attention 연산을 수행하는 과정에서 문맥 정보는 학습되지만, 위치 정보는 학습할 수 없습니다. 따라서 애초에 Attention 연산을 수행하기 전에 위치 정보를 벡터에 포함해야 합니다. 이를 Positional Encoding이라고 하는데, 쉽게 말해서 위치 정보를 벡터에 포함하므로써 하나의 문장안에서 똑같은 형태의 벡터가 등장해도 연관도를 가지는 벡터는 달라지는 것 입니다.
그럼 이제 Self-Attention의 동작 과정입니다.
-
어텐션 스코어 계산: 특정 요소의 문맥적 표현을 계산하기 위해, 해당 요소의 Q(Query) 벡터를 집합 내 모든 요소의 K(Key) 벡터와 내적(dot-product)하여 스코어를 계산합니다. 이 과정은 모든 Query와 Key 벡터를 각각 행렬 Q,K로 묶어 연산을 통해 효율적으로 한 번에 계산됩니다. 이때 어텐션 스코어로 생성된 행렬을 어텐션 맵(Attention Map)이라고도 합니다.

출처: https://slds-lmu.github.io/seminar_nlp_ss20/attention-and-self-attention-for-nlp.html 어텐션 맵의 예시 사진.
-
스케일링 및 정규화: 계산된 어텐션 스코어는 K 벡터의 차원에 따라 크기가 달라질 수 있으며, 이는 학습 과정을 불안정하게 만들 수 있습니다. 따라서 이를 방지하기 위해 스코어를 K 벡터 차원의 제곱근으로 나누어 스케일링(scaling) 합니다. 이후, 스케일링된 스코어에 소프트맥스(Softmax) 함수를 적용하여 모든 값의 합이 1이 되도록 정규화합니다.
-
가중 합을 통한 출력 벡터 생성: 마지막으로, 각 요소의 V 벡터에 해당하는 어텐션 가중치를 곱한 후 모두 더하여, 요소 i에 대한 최종 출력 벡터를 생성합니다. 이 출력 벡터는 집합 내 모든 요소의 정보를 담고 있지만, 자신과 관련성이 높은 요소들의 정보가 더 많이 반영된, 문맥적으로 풍부한 새로운 표현입니다.
이렇게 Self-Attention을 통해 생성되는 벡터를 일반화 된 공식으로 도출한다면 아래와 같습니다.
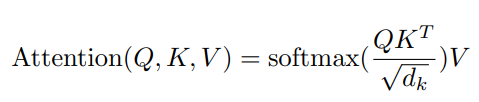
일련의 과정을 모두 거치고 나서 생성된 최종 벡터는 이제 문맥 손실 없이 문맥 정보와 위치 정보를 잘 포함하는 값을 가지게 됩니다.
결론
이번 게시글에서는 RNN 모델 중 하나인 Seq2Seq의 문제점을 해결하기 위해 등장한 Attention Mechanishm과 부딪힌 한계. 또 그 한계를 극복하기 위해 등장한 Self-Attention이라는 메커니즘을 살펴보았습니다.
실제로 Self-Attention 메커니즘을 현대 대부분의 많은 LLM과 LMM(Large Multimodal Model)이 채택중이며, NLP 분야를 혁신적으로 성장시키는데 큰 기여를 했다고 말할 수 있습니다.
이렇게 실제로 Attention과 Self-Attention이 동작하는 구조를 살펴보고 나니 왜 LLM의 문장 생성은 확률의 연속이라고 말하는지 조금은 알 것 같습니다. 사실 이것을 조금 더 이해하기 위해서는 Transformer 모델에 대해서 살펴봐야 하는데, 다음 Post에서는 이 Transformer 모델에 대해서 분석하고 알아보고 싶습니다.
참고 자료
- Attention Is All You Need - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin | Original paper
- Attention/Transformer 시각화로 설명 | ImcommIT youtube channel
- 트랜스포머, ChatGPT가 트랜스포머로 만들어졌죠. - DL5 | 3Blue1Brown 한국어 youtube channel
- 그 이름도 유명한 어텐션, 이 영상만 보면 이해 완료! - DL6 | 3Blue1Brown 한국어 youtube channel
- [딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) | 동빈나 youtube channel
- 의외 다수 LMM과 인터넷을 통해 학습한 자료들.