
GPT와 BERT, 트랜스포머 모델의 2인자
개요
우리 일상에서는 남녀노소를 불문하고 모두가 아는 AI가 한가지 있습니다. 바로, GPT, Generative Pre-Tranied Model 일명 ChatGPT 입니다. ChatGPT는 OpenAI에서 출시한 딥러닝 모델로, 글을 작성하는 시점인 2025년 9월 27일을 기준으로 많은 사람들이 알고, 듣고, 사용합니다.
저는 글을 작성하는 시점 10대 후반이기에, 새로운 문물을 자주 접하는 환경에 노출되있고, 자연스럽게 2021년~2022년 부터 ChatGPT라는 인공지능을 봐왔습니다. 그때는 우리나라에 이미 존재하던 인공지능 서비스인 '심심이', '이루다'와 같은 수준의 단순한 말장난 할수 있는 장난감 정도라는 인식이였던 것으로 기억합니다.
하지만 2023년 부터, 학교 선생님이 ChatGPT라는 것을 언급하기 시작하면서, 점점 시간이 지나 2024년, 2025년 현재에 와서는 뉴스, 부모님, 나이가 꽤있으신 어른분들께서도 ChatGPT를 알고 사용하는 모습을 보니 정말 신기하였습니다.
이러한 ChatGPT가 많은 사람들의 구설수에 오를때는 '챗봇', '생성형AI', '대화형 인공지능'과 같이 여러 용어로 사용되는데, 사실 정확한 용어는 저번 Post에서 우리가 다뤘던 모델인 Transformer, 정확히는 Transformer 기반 모델이라는 사실입니다.
2017년 트랜스포머 모델 등장이후, NLP를 위한 수많은 모델들이 등장하면서, 2018년, 2019년 해를 거듭할 수록 비약적으로 성장하기 시작했습니다. 그때 등장한 주요 모델이 바로 GPT(Generative Pre-Tranied Model)와 BERT(Bidirectional Encoder Representations from Transformers)모델 입니다.
따라서 오늘 게시글에서는 GPT와 BERT 모델이 무엇인지 살펴보고, 어떤 구조를 가지는지도 함께 살펴보겠습니다.
사전 학습, 미세 조정, 전이 학습의 시작
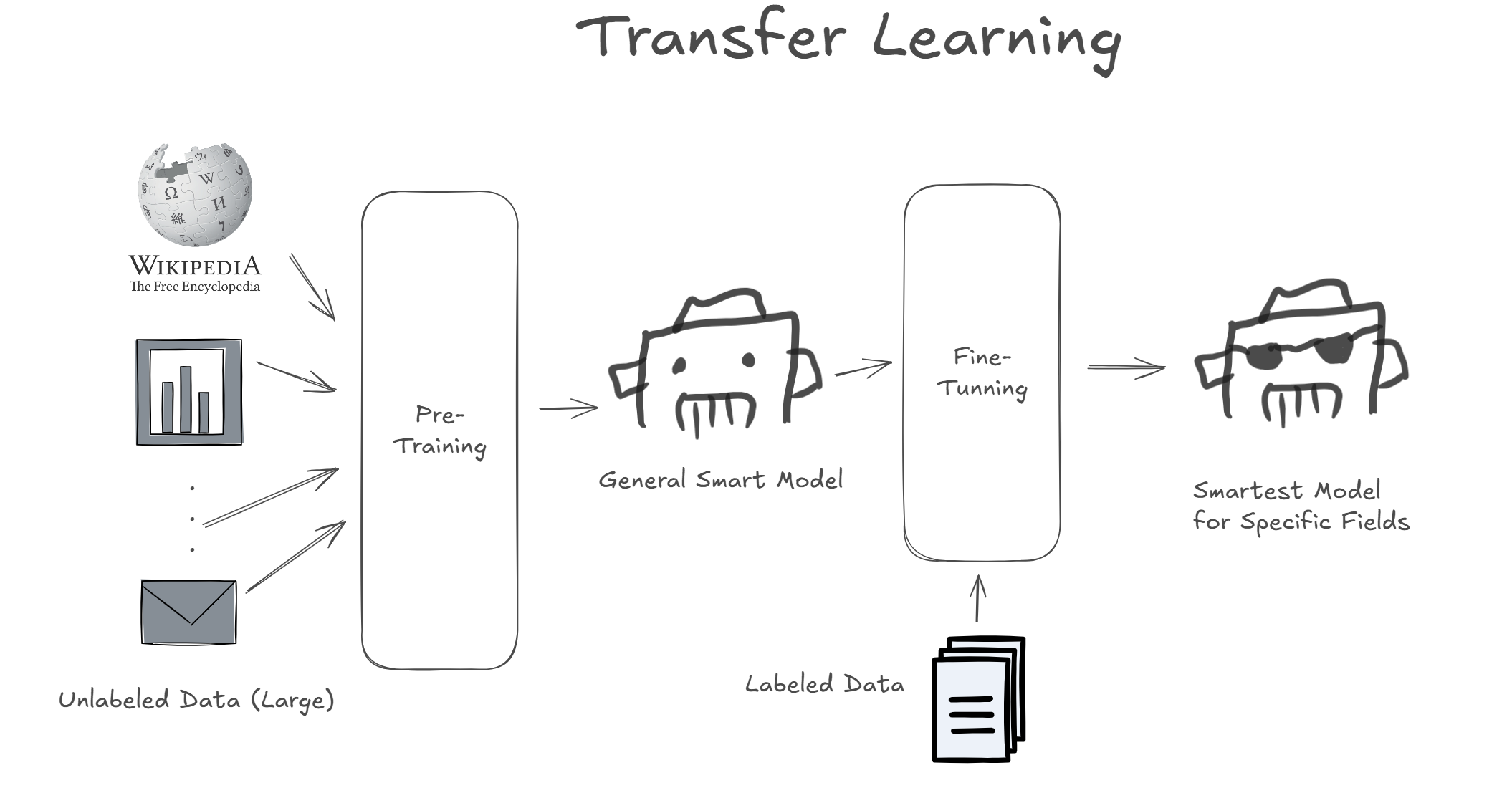
먼저 GPT와 BERT를 살펴보기 전에, GPT와 BERT에 대한 특징 몇가지를 알고가야 이해하기 쉽습니다. GPT와 BERT는 사전 학습(Pre-training), 미세 조정(Fine-tuning), 전이 학습(Transfer Learning) 이라는 세가지 패러다임을 통해 NLP 분야에 새로운 관점을 시사했습니다.
각각 하나씩 무엇인지 살펴보겠습니다.
사전 학습(Pre-training)
사전 학습(Pre-training)이란, 모델을 특정한 목적을 위해, Label을 가진 Supervised Learning 기법을 사용하여 모델을 학습 시키는 것이 아닌, 일단 Label이 없는 상태의 방대한 양의 데이터를 Unsupervised Learning을 통해 학습 시키는 기법입니다. 이는 지금껏 딥러닝 분야의 대세였던 '완전 학습' 기법(모델을 처음부터 끝까지 특정한 목적으로 학습)에 대비되는 시도였습니다.
인터넷에 존재하는 위키피디아, 뉴스 등 많은 자료들을 가지고 예측하도록 모델을 학습시킵니다. 이는 보통 막대한 컴퓨팅 자원이 소모되기에 기업이나 연구소 수준에서 가능하다고 합니다. 이 때부터 LLM(Large-Language-Model)이라는 방대한 양을 학습한 언어 모델이라는 개념이 등장했습니다.
미세 조정(Fine-tuning)
미세 조정(Fine-tuning)이란, 사전 학습(Pre-training)된 모델을 특정 문제(분류, 감정 분석, 문장 생성 등)를 해결하기 위해 정답이 존재하는 보다 소규모 데이터셋으로 Supervised Learning을 통해 학습 시키는 방법 입니다.
이렇게 미세 조정을 진행하는 모델은 이미 방대한 양의 데이터로 여러 분야에 대한 일반적으로 좋은 성능을 나타내는 모델이기 때문에, 특정 분야에 대한 소규모 데이터셋으로 지도 학습을 진행하면 특정 문제를 해결하기 위한 모델이 탄생합니다.
전이 학습(Transfer Learning)
전이 학습(Transfer Learning)은 이렇게 딥러닝 모델을 사전 학습시키고, 이후 미세 조정으로 특정한 분야의 문제를 해결하기 위한 특별한 모델을 학습시키는 전체 과정을 일컫는 말입니다.
이러한 전이 학습의 개념은 논문 "Deep Belief Networks"에서 Dr. Geoffrey E. Hinton이 제안하였고, 2018년 ~ 2019년경 NLP 분야에서 활발히 사용되기 시작했습니다.
GPT와 BERT 역시 이러한 전이 학습을 적극적으로 사용하였고, 이후 많은 모델이 NLP 분야에서 전이학습을 사용하기 시작했습니다.
GPT와 BERT, Encoder vs Decoder
GPT와 BERT는 트랜스포머 모델이라는 근본적인 뿌리에서 각자 조금씩 다른 형태로 모델의 구조를 완성해나갔습니다.

Transformer 모델에서, 인코더와 디코더는 역할을 나눠보면 다음과 같습니다.
- 인코더(Encoder): 문장의 모든 단어간의 관계를 압축해서 문장의 정보를 최대한 이해하려고 노력함.
- 디코더(Decoder): 문장을 생성하기 위해 문장 단어 관계를 분석하고 가장 확률성이 높은 다음 단어를 추출, 이 과정에서 인코더의 정보가 필요.
즉, 한 문장으로 인코더는 '정보 요약'을 중점에 두고, 디코더는 '정보를 통한 확률성 추측'에 중점을 두고 있습니다. 여기서 GPT와 BERT는 각각의 인코더와 디코더의 특징을 잘 살리도록 아예 다른 한쪽을 제거해서, 남은 한쪽의 장점을 극대화 하는 방식으로 모델의 구조를 채택했습니다.
GPT는 인코더를 제거함으로써, 문장 생성이라는 디코더의 역할의 중점을 두었고, BERT는 디코더를 제거함으로써 문장내에 관계와 문맥 추출이라는 인코더의 장점을 극대화했습니다.
그렇다면 어떻게 GPT와 BERT가 각각 인코더와 디코더를 제거하면서 우수한 성능을 발휘하도록 구성되었는지 살펴보겠습니다.
GPT, 확률 게임의 달인 디코더 🎰
GPT는 당시 비영리 연구 조직이던 OpenAI가 2018년에 발표한 논문인 "Improving Language Understanding by Generative Pre-Training"에서 처음으로 발표된 모델입니다.
앞서 언급한 것 처럼 이 논문에서 알렉 래드포드(Alec Radford)를 비롯한 연구진은 비지도 학습(unsupervised learning) 방식으로 대규모 텍스트 데이터셋을 학습한 후, 특정 과제(task)에 맞게 미세 조정(fine-tuning)하는 방법을 제시했습니다. 이를 통해 하나의 범용적인 모델로 다양한 자연어 처리 문제를 해결할 수 있는 가능성을 열었습니다.
이런 GPT는 인코더를 제외하고 디코더의 생성 능력을 극대화 하는 구조로 설계되었는데요, GPT의 구조에 대해서 조금 자세히 살펴보도록 하겠습니다.
GPT 구조

해당 사진의 좌측에서는 GPT의 전체적인 구조를 보여주고 있습니다. 또한 우측에서는 Transfomer Block Layer의 세부적인 구조가 어떻게 구성되었는지 보여주고 있습니다. 이는 매우 복잡해 보이지만 실제로는 단순한 구조를 가지는데요, 하나씩 살펴보겠습니다.
Input Embedding + Positional Embedding
이는 모든 트랜스포머 모델이 그렇듯, 특정 시퀀스를 컴퓨터가 이해할 수 있는 토큰으로 분리하고, 분리된 토큰을 벡터화 한 뒤에, 위치 정보를 인식하도록 Positional Encoding을 해주는 과정입니다.
해당 단계를 거치고 나면 시퀀스는 컴퓨터가 의미를 파악하기 좋은 단위의 위치 정보를 포함하고있는 벡터 값들로 출력됩니다.
Dropout
이렇게 생성된 벡터의 일부 값들을 랜덤하게 0으로 만드는 Dropout을 수행합니다. Dropout을 수행하는 이유는 Dropout을 수행함으로써 벡터의 일부 차원들을 랜덤하게 무의미하게 만들고, 모델이 과적합하는 것을 방지해 줍니다.

Transformer Block에는 마지막에 벡터에 Dropout이 적용되도록 하지만 초기에 Transformer 모델로 입력되는 벡터는 해당 Layer를 거치지 못하기에 이렇게 따로 Dropout을 수행 해주는 것 입니다.
여기서 질문: 만약 Dropout으로 인해 중요한 정보를 띄는 벡터 차원이 out 되면 어떡하죠??
사실 바로 이것이 Dropout이 유도하는 목적이자 의도입니다.
예를 들어 상황을 하나 가정해보록 하겠습니다. 당신은 지금 교실에 있는 선생님입니다. 당신의 교실에는 수많은 학생이 있으며, 이 수 많은 학생들중 유난히 공부를 잘하는 몇명의 학생(많은 정보를 가지는 벡터 차원)들이 존재합니다. 당신은 학생들에게 수학 문제를 풀게 하고, 다 푼 학생에게는 보상을 주고, 보상을 받은 학생은 더욱 똑똑해지는 사탕을 받습니다. 이 과정을 반복하다 보면, 결국 원래 똑똑했던 학생들이 계속해서 사탕을 먹게되고, 보상은 편향되게 됩니다.
이것을 방지하기 위해서, 한가지 룰을 추가하면 됩니다. 랜덤으로 몇명의 학생들은 이번 차례에 문제 푸는 것을 쉬게하는 것입니다. 바로 이것이 Dropout 입니다.
따라서 Dropout은 이러한 매커니즘으로 과적합을 방지함으로써 모델이 안정적이고 평균적인 성능을 내도록 합니다. 또한 Dropout은 학습시에만 적용되므로, 추론 단계에서는 모든 벡터 차원의 의미를 보장하여 최적의 결과를 반환하도록 합니다.
Transformer Block
GPT 구조에서 Transformer Block은 크게 두가지 부분으로 나뉩니다.
- Masked Self-Attention Layer
- Feed Forward Neural Network
사실 이두가지 계층들은 원래 Transformer 모델의 디코더와 거의 유사하며, 조금의 차이가 있습니다. 각각 살펴보겠습니다.
먼저 Masked Self-Attention Layer는 우리가 잘 알고있는 구조의 Masking을 적용한 Self-Attention 입니다. Masking을 적용해서 학습시에는 생성 해야하는 토큰 이후부터 문장의 끝 까지의 정보들은 컨닝하지 않고, 오직 생성해야하는 토큰 이전까지의 정보를 최대한 압축하고 가중하는 방향으로 가중치 행렬(Q, K, V)을 학습 시킵니다.
이렇게 학습된 가중치 행렬로 생성된 마지막 토큰은 다음 토큰을 생성하기 위해 필요한 정보를 최대화 하는 방향으로 학습합니다. 또한 Multi-Head 구조를 통해 더욱 학습의 효율성과 정확성을 극대화 시킵니다.
생성된 벡터는 Dropout을 적용하고, Add & Norm을 수행해 잔차학습과 정규화를 진행한뒤 다음 FFN 계층에 전달됩니다.
다음으로 Feed Forward Neural Network에서는 어텐션을 통해 얻은 문맥 정보를 바탕으로, 각 단어의 의미를 개별적으로 한 번 더 깊게 처리하고 변환하는 역할을 합니다. 첫번째 Linear 계층에서는 차원을 확대시키고, 활성화 함수 GeLU를 통해 비선형적으로 출력을 만든 뒤 다시 두번째 Linear에서는 원본 벡터 수준으로 차원을 축소합니다.
이후 다시 Dropout을 진행, Add & Norm을 수행해 잔차학습과 정규화를 진행한뒤 다음 계층에 전달됩니다.
Transformer Block의 내부는 이러한 구조를 가지며 GPT-1의 경우 Transformer Block이 12개 정도 쌓여있다고 합니다.
LayerNorm
여러 Transformer Block을 거친 벡터가 특정 범위에 치우치지 않도록 정규화하여 학습 과정을 안정시킵니다.
Linear + Softmax

Softmax에서는 처리된 벡터를 모델이 아는 모든 단어의 개수만큼 차원을 확장시켜, 각 단어가 정답일 확률을 계산하기위해 마지막 Linear 계층에서 결과값을 확률로 변환합니다. 모든 단어의 확률값을 더하면 1이 되도록 만들어, 이 중 가장 확률이 높은 단어 하나를 다음 단어로 예측합니다.
이후 생성된 단어를 현재까지 생성된 시퀀스에 포함시켜 다음 단어를 예측하기 위한 Input으로 사용합니다.
GPT 요약
GPT는 인코더를 제거함으로써, 효율적인 문장 생성이 가능해졌고, Transformer Block에 Masked Self-Attention 기법을 통해 최적화 된 학습을 수행, 추론시에도 뛰어난 성능을 발휘하도록 하였습니다.
GPT는 주로 파인튜닝하여 챗봇, 콘텐츠 제작, 텍스트 요약, 기계 번역같은 분야에서 사용됩니다.
하지만, 디코더 특성상 단방향 Left->Right으로 단어를 생성하는 구조를 가졌기 때문에, 전체적인 문맥 파악에는 한계가 있을 수 있습니다.
BERT, 남다른 눈치의 인코더 👀
BERT는 2019년 구글 AI 언어팀의 연구원들이 작성한 논문 "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"에서 공개된 모델입니다.
BERT의 이름 'Bidirectional Encoder Representations from Transformers'에서 알 수 있듯, 트랜스포머 인코더의 구조를 기반으로 하는 양방향 문맥 학습 위한 모델입니다.
GPT는 문장 생성에는 탁월하지만, 문맥 파악에는 어쩔수 없이 Masking 구조상 한계를 겪을 수 밖에 없는 문제가 있습니다.
GPT는 마스킹 때문에 데이터가 Left -> Right으로 점점 하나씩 공개되는 것을 보고 추론해야합니다. 즉, 뒤에있는 정보들이 마스킹되어서 가려지기에, 오직 앞에있는 정보들까지의 종합으로 문맥을 파학하죠. 이러한 방식에는 한계가 있을 수 있습니다.
예를 들어 GPT 모델을 이용해, "The cat sat on the TV"라는 문장이 있을때, 문맥을 파악해야한다고 합시다. 해당 데이터는 마스킹으로 인해 "The cat" , "The cat sat"과 같은 순서로 점점 뒤에 단어가 하나씩 공개될 것 입니다. 하지만, "The cat sat on" 까지만의 데이터를 보고 문맥을 파악하기는 어렵죠. 이것이 바로 GPT의 문맥의 한계입니다. 오직 Left의 문맥 정보를 참고해야하죠. 하지만 이것도 Self-Attention으로 일정 수준 커버가 가능해서 Left의 정보를 최대한 활용해 문맥을 예측하곤 합니다.
결국 BERT는 이러한 방향에 제한이 없는 즉, Masking이 없는 Self-Attention을 사용하는 인코더를 채택해서 문맥 파악의 성능을 극대화한 모델이 된 것 입니다.
이제 부터 BERT는 어떠한 구조로 구성되었는지 살펴보겠습니다.
BERT 구조

BERT는 Size에 따라서 크게 두가지로 분류합니다. BERT Base와, BERT Large로 분류합니다.
BERT Base와 Large는 단순히 Multi-Head Attention와 Feed Forward 계층들을 포함한 하나의 BERT Layer가 몇개 쌓였는가에 대한 차이입니다. BERT Base의 경우 12개의 Bert Layer를 사용해서 110만개의 파라미터를 사용하게 되고, BERT Base의 경우 24개의 Bert Layer를 사용하기 때문에 340만개의 파라미터를 사용합니다.
BERT Layer는 정말 단순히 우리가 알고있는 Multi-Head로 진행되는 Self-Attention Block과, FFN, 그리고 잔차학습과 정규화를 위한 Add & Norm의 구성으로 트랜스포머의 인코더와 완전히 동일 합니다.
하지만 BERT는 입력 데이터와 출력 데이터가 무엇이냐에 따라서 모델의 일종의 형태가 바뀌는 것이 특징인데요, 사전 학습된 BERT는 크게 두가지 작동 형태가 존재합니다.
- MLM (Masked Language Model)
- NSP (Next Sentence Prediction)
이 두가지 작동 형태에 따른 BERT의 동작과정을 살펴보겠습니다.
MLM (Masked Language Model)
MLM(Masked Language Model)은 BERT가 문장의 일부를 가지고 Masked된 특정 토큰을 양방향 문맥을 통해 찾아나가는 작동 방식입니다.
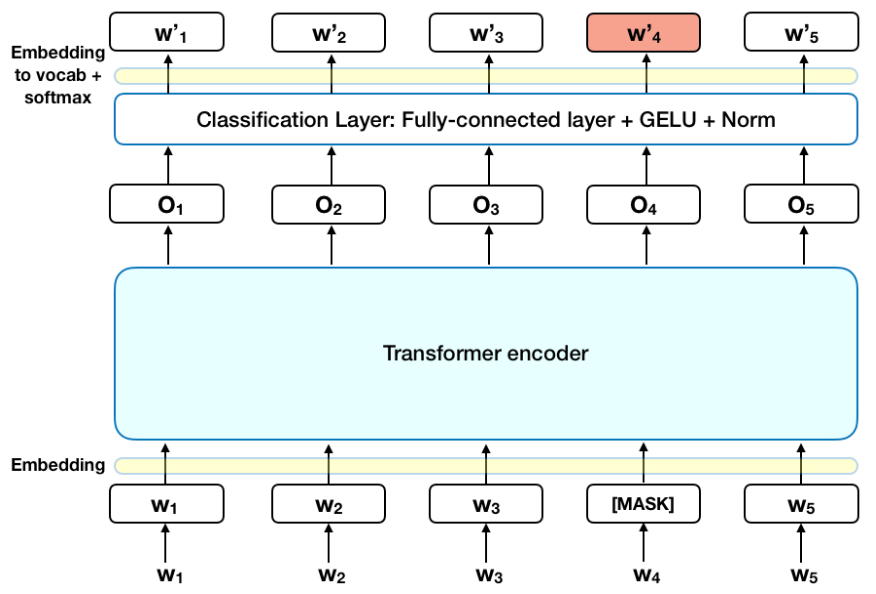
해당 사진이 MLM으로 BERT 모델을 사용하고 있는 모습인데요, 각각의 W1~W5가 토큰인데, 여기서 W4가 [MASK]로 Masking 된 형태입니다. 이 Masking된 토큰인 [MASK]를 찾아내기 위해서 BERT는 Self-Attention을 진행하여 양방향 문맥을 포함하고, 최종적으로 가중치를 업데이트 하게 됩니다.
이렇게 학습된 BERT는 특정 부분이 [MASK] 되었을때 최대한 학습된 가중치를 통해 유사도가 높은 토큰을 선택해 출력합니다.
실제로 저도 다국어 BERT 모델인 bert-base-multilingual-cased를 이용해서 MLM을 시도해보았습니다.
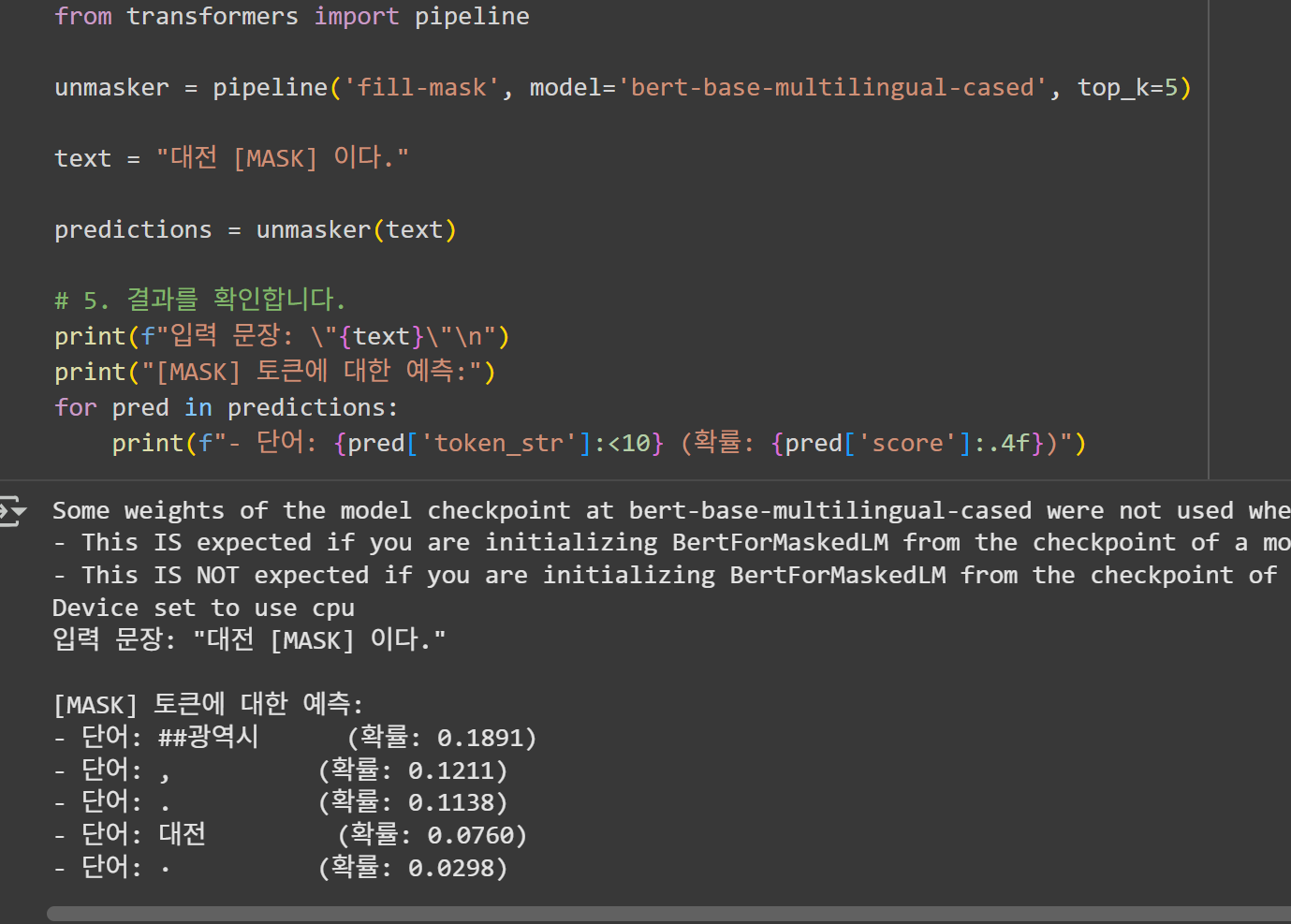
이렇게 대전과 연관있는 '##광역시'(여기서 ##는 BERT의 임베딩 모델로 인해 생기는 현상으로 여러 형태의(서울, 부산 등) 토큰뒤에 붙을 수 있는 토큰이라는 의미입니다.)가 가장 큰 확률로 예측되는 것을 볼수 있습니다.
NSP (Next Sentence Prediction)
NSP(Next Sentence Prediction)는 두가지 문장이 주어졌을때, BERT가 두 문장이 연결되었는지(IsNext), 혹은 서로 다른 이어지지 않는 별개의 문장인지(IsNotNext) 분류하는 모드입니다.

위 사진은 BERT 모델을 통해 두가지 문장이 이어지는지, 이어지지 않는지 추론하고 있는 모습입니다.
첫번째 문장의 시작에는 [CLS]라는 토큰을 붙이고, 첫번째 문장이 끝나고 두번째 문장이 시작되는 부분에는 [SEP] 토큰을 넣어서 두가지 문장을 BERT가 구분할 수 있게 해줍니다.
또한 NSP를 위해서 특별히 각 토큰에 Segement Embedding을 더합니다, Segement Embedding은 각 토큰이 첫번째 문장인지, 두번째 문장인지 구분하기 위한 토큰으로 Self-Attention을 진행할때 이 세그먼트 토큰별로 토큰을 구분합니다.
BERT는 Attention을 통해 두 문장이 연관이 있는지 확인하고 최종적으로 [CLS] 토큰의 최종 출력 벡터로 두 문장이 연결되었는지(IsNext), 서로 다른 이어지지 않는 별개의 문장인지(IsNotNext) 반환하게 됩니다.
BERT 요약
BERT는 Transformer 모델의 인코더의 Self-Attention을 적극적으로 활용하여 양방향 문맥을 모두 활용해서 문장의 특정 가려진 단어를 예측하거나, 두 문장의 연관 관계를 예측하는 두가지 목표를 높은 성능으로 달성하였습니다.
이러한 BERT 모델은 파인 튜닝을 통해 여러 분야에서 특화해서 사용이 가능합니다.
BERT는 특히 문맥 파악, 내용 요약, 텍스트 분류와 같은 분야에서 많이 사용됩니다.
GPT와 BERT, 현대에는 어떻게 되었을까?
이렇게 GPT와 BERT에 대해 알아보았습니다. 각각 인코더와 디코더를 제거함으로써 인코더, 디코더만의 장점을 극대화하였지만, GPT는 문맥파악에 한계를 맞닥트렸고, BERT는 문장 생성에 한계를 맞닥트리게 되었습니다.
하지만 글을 작성하는 2025년 기준으로 GPT와 BERT는 어떻게 발전하였을까요? 사실이미 우리는 정답을 알고있습니다. 우리는 이제 현재 최신 모델인 GPT-5에게 문맥 파악, 내용 요약, 텍스트 분류 처럼 초기 GPT-1이 절대로 해낼수 없을 것 같았던 일들을 시킵니다. 어떻게 이게 가능해진 걸 까요?
그 시작은 2020년 출시된 GPT-3를 통해 완전히 패러다임이 변경되었습니다. GPT-3는 175B 1750억개의 파라미터를 사용하면서 BERT 수준의 이해력에 도달할 수 있다는 것을 증명했습니다. 또한 프롬포트만 잘 처리하면 이제 파인튜닝 없이도 특정한 태스크를 전문가 수준급으로 처리가 가능하다는 것을 증명했죠.
따라서 GPT-3와 같은 대규모 파라미터로 학습된 LLM(Large-Language-Model)이 NLP에서 범용적인 Task들을 수행할 수 있다는 것을 증명했으며, BERT는 특정 분야에서는 여전히 사용되고있으나 GPT는 이제 한계를 많이 극복한 모델이 되었습니다.
결론
이번 Post에서는 트랜스포머를 필두로 Encoder-Only 모델인 BERT, Decoder-Only 모델인 GPT가 어떤 구조로 되어있고, 어떤 동작 방식을 취하는지 알 수 있었습니다.
특히 이렇게 디코더와 인코더에 강점을 살리는 구현방식이 신기했으며, 트랜스포머가 정말 혁신적인 모델이였고 역사에 남을 모델이였다고 다시한번 되새기게 되는 것 같습니다.
또한 제가 사용중인 GPT-5는 아니지만 GPT라는 모델의 기본적인 구조와 유래가 어떻게 되있는지 알 수 있어서 흥미로운 시간이였습니다.
다음 게시글에서는 GPT-1이 아닌 파라미터수를 늘려서 돌아온 GPT-2를 간단하게 분석해보고, 파인 튜닝까지 해보도록 하겠습니다.
참고 자료
- Introduction to Generative Pre-trained Transformer (GPT) | GeeksforGeeks
- Encoder-Only Transformers (like BERT) for RAG, Clearly Explained!!! | StatQuest with Josh Starmer youtube channel
- [딥러닝 자연어처리] BERT 이해하기 | Minsuk Heo 허민석 youtube channel
- BERT와 GPT의 개요 | 서울시립대학교 DS플러스 사업단 youtube channel
- 의외 다수 LMM과 인터넷을 통해 학습한 자료들.